How DataCater Works
DataCater is the simple yet powerful approach to building real-time data pipelines: Data and developer teams report that they save more than 40% of the time spent on crafting data pipelines.

DataCater is the simple yet powerful approach to building real-time data pipelines: Data and developer teams report that they save more than 40% of the time spent on crafting data pipelines.
DataCater's approach
DataCater is the modern, real-time data pipeline platform, which allows data and developer teams to iterate on data pipelines in seconds and deploy them to production in minutes.
Data and developer teams use DataCater's Pipeline Designer to clean, filter, enrich, join, and transform data with no-code building blocks or custom Python® functions. Full support for interactive previews while you build data pipelines is included!
DataCater compiles data pipelines to lightweight streaming applications that can be integrated with Apache Kafka® and other data systems. DataCater offers plug & play change data capture for source connectors.
One-click deployments allow users to ship streaming data pipelines to production without worrying about complicated or long-running deployment processes. DataCater takes care of running your data pipelines in production, on top of Kubernetes, and offers fine-grained logging, monitoring, and alerting.

Core features
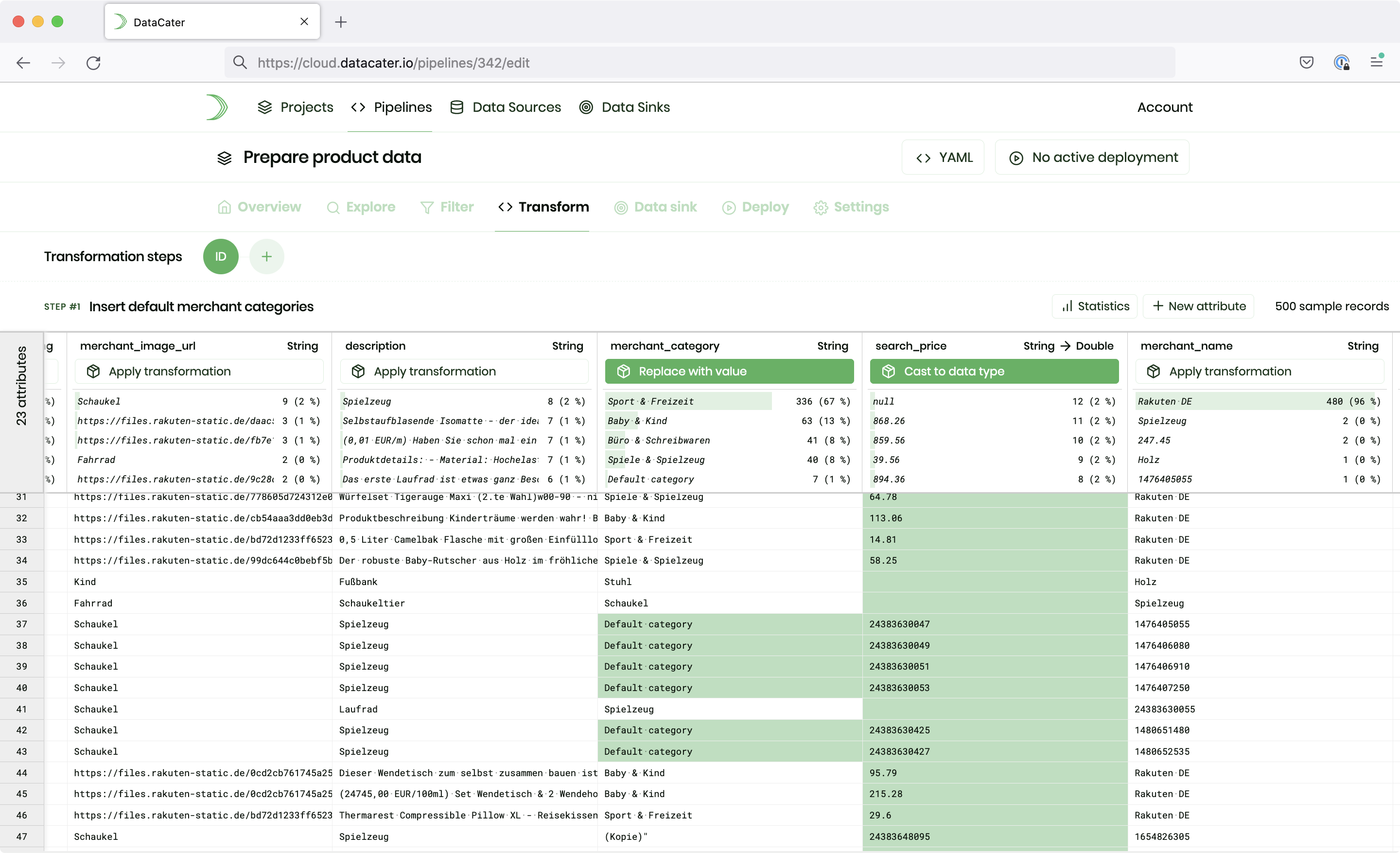
Interactive Pipeline Designer
Build production-ready streaming data pipelines with DataCater's Pipeline Designer. Transform, filter, and enrich data according to your business rules and requirements, with no-code building blocks or Python®.
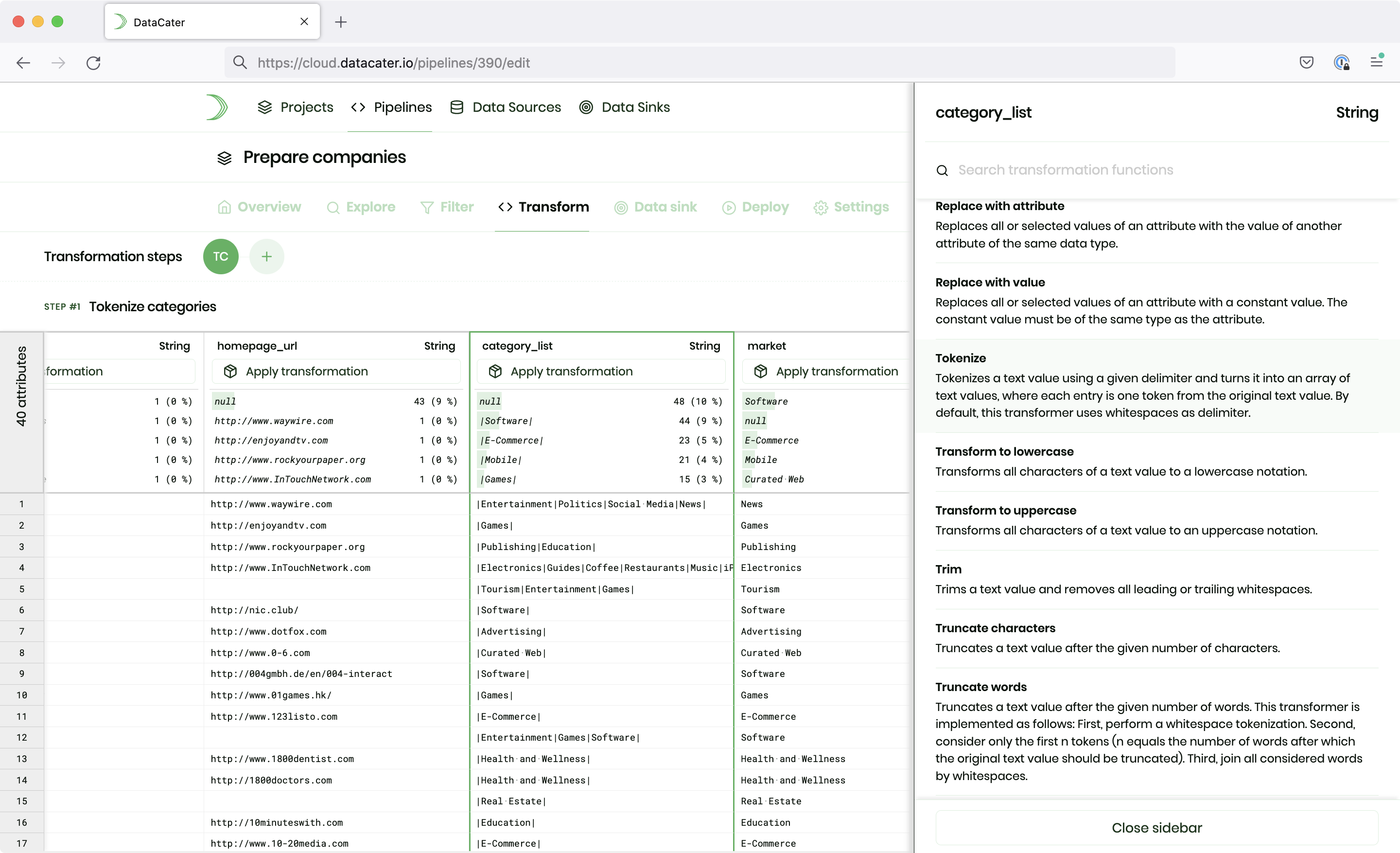
Python® transforms
Implement custom requirements with Python®-based transformations. DataCater's Pipeline Designer allows users to interactively preview, validate, and refine code-based transformations.
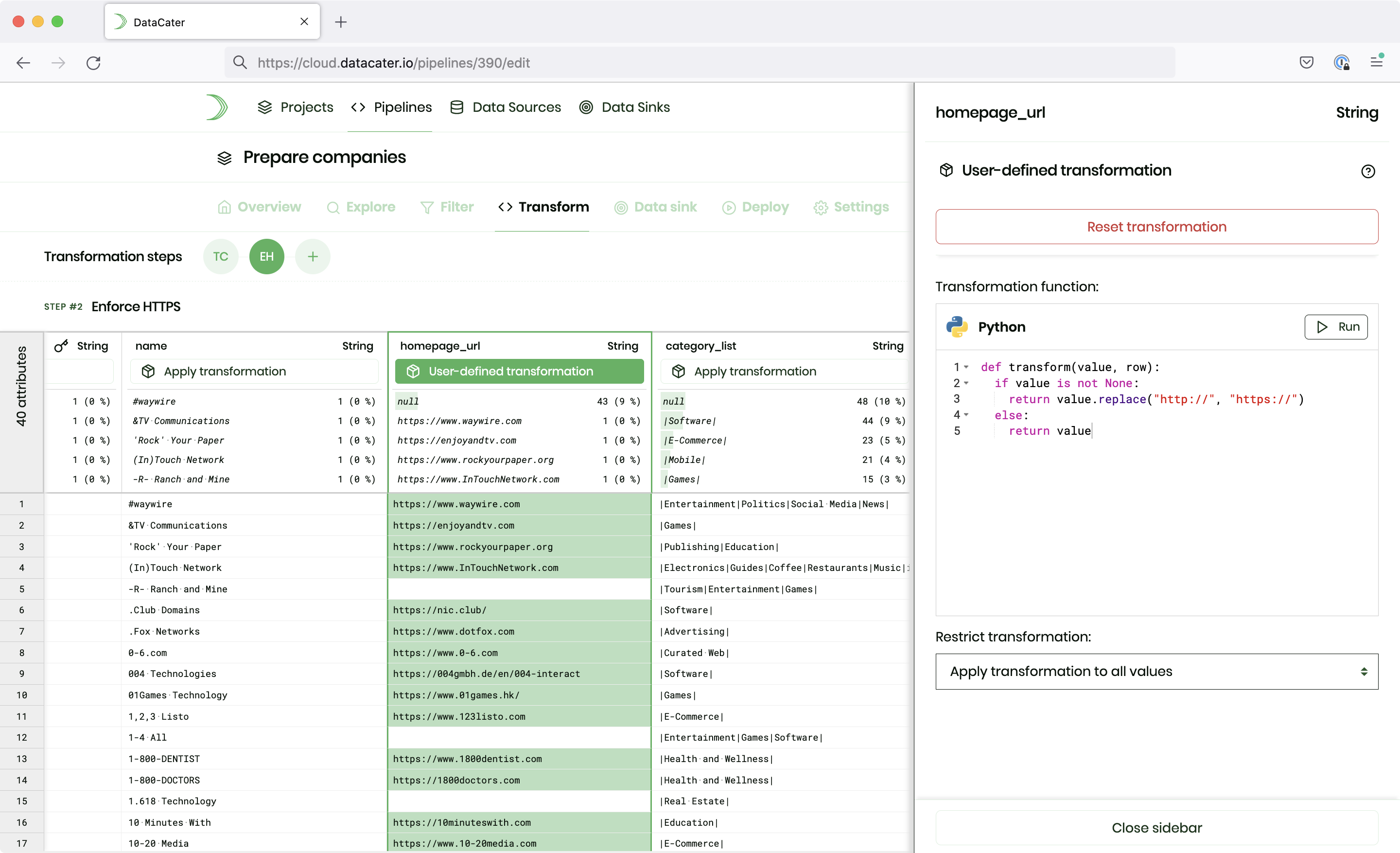
Plug & play connectors for change data capture
Improve the robustness and efficiency of your data pipelines by streaming data changes (INSERTs, UPDATEs, and DELETEs) instead of employing error-prone bulk imports.
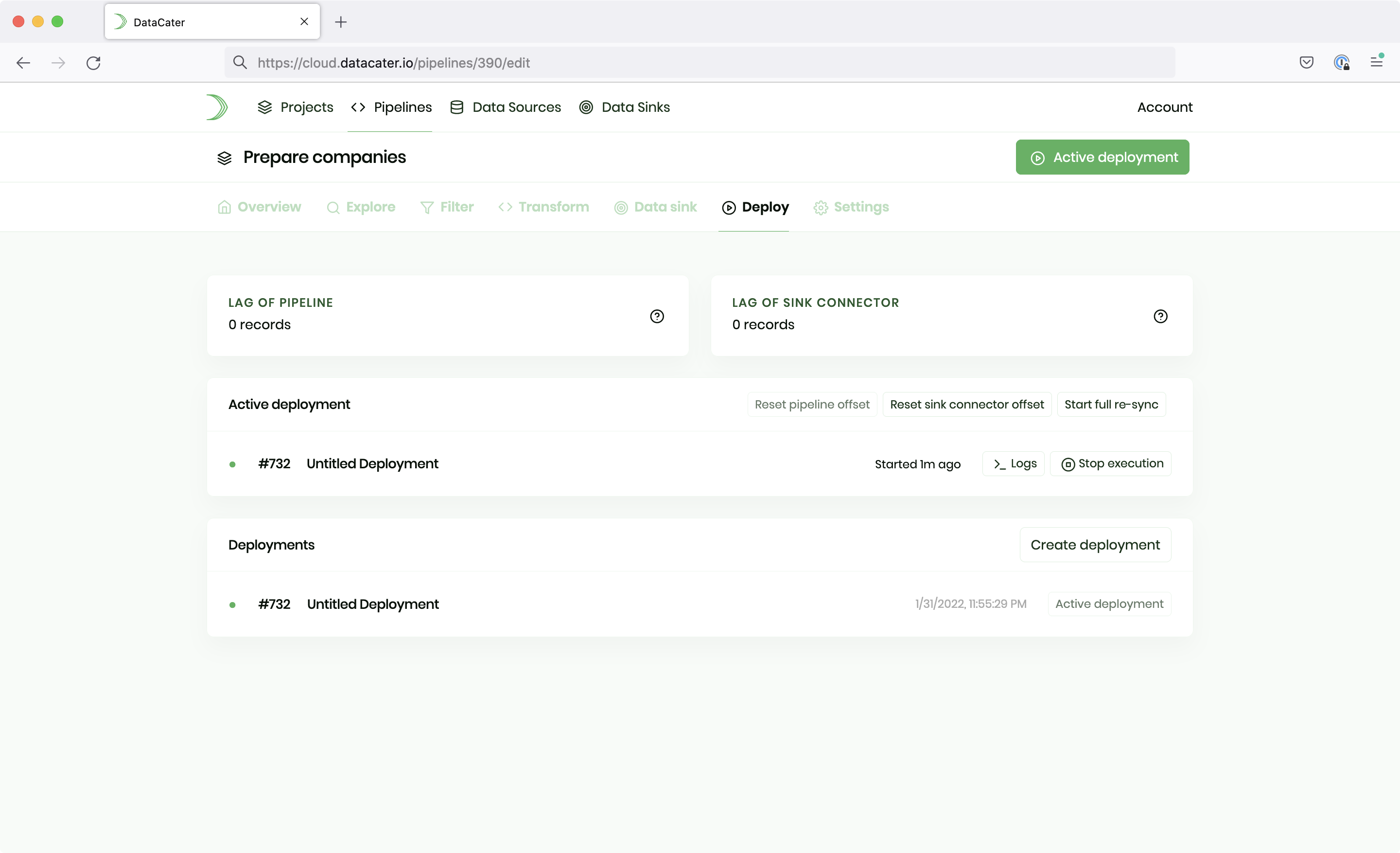
One-click deployments
Deploy streaming data pipelines to production with one click. Access pipeline logs and benefit from continuous monitoring for smooth operations and full transparency.
Before vs. after DataCater
| Before DataCater | After DataCater |
|---|---|
| Waste time on manual tasks: Streaming experts build and automate streaming data pipelines manually, wasting lots of time on repetitive work, like configuring connectors or setting up deployments. Building and deploying a data pipeline to production takes days to weeks. |
Accelerate data development: DataCater enables developers to connect data systems and automate data preparation in a few minutes, using pre-built transforms or Python®. One-click deployments compile data pipelines to optimized streaming applications and minimize the time to production to minutes. |
| Streaming experts are the bottleneck: Business people specify requirements for data, which are implemented by streaming experts via manual coding. Specialists are a scarce resource and resemble the bottleneck for organizations trying to work with current data. |
Everyone can build data pipelines: DataCater makes streaming data pipelines accessible to data and developer teams. Using DataCater's Pipeline Designer, they can process data with pre-built transforms or apply custom Python® functions. |
| Work with outdated data: Data pipelines perform error-prone bulk loads at a low frequency, leaving data sinks almost always out of sync with data sources. Downstream applications and data consumers cannot leverage up-to-date data in their decision-making, leading to frustration and a poor ROI for analytics/data initiatives. |
Benefit from fresh data: DataCater makes streaming data pipelines a commodity for data and dev teams. Data pipelines stream change events from data sources to data sinks in real-time and allow downstream applications and data consumers to always use fresh data. |
More features
Say goodbye to knowledge silos and prepare data together. DataCater provides projects as a collaborative means and allows data experts to work simultaneously on data pipelines.
DataCater monitors all connectors and pipelines continuously. All processed data are available through the logs of a pipeline deployment. Once an outage is detected, DataCater can send instant notifications to users via e-mail or Slack.
Pipeline deployments write all processed data to a log, which is accessible through the Pipeline Designer but can also be integrated with existing logging solutions.
The Enterprise plan of DataCater offers a fine-granular audit log, which provides insights into all actions performed by the users of a specific organization on DataCater.
DataCater is built for the cloud era and provides native integrations into the major cloud platforms. We are happy to help you to deploy a private DataCater instance inside your cloud environment.
DataCater is based on Apache Kafka®, the industry standard for storing and processing event data. Benefit from the efficiency and power of stream processing without wasting time on repetitive work.