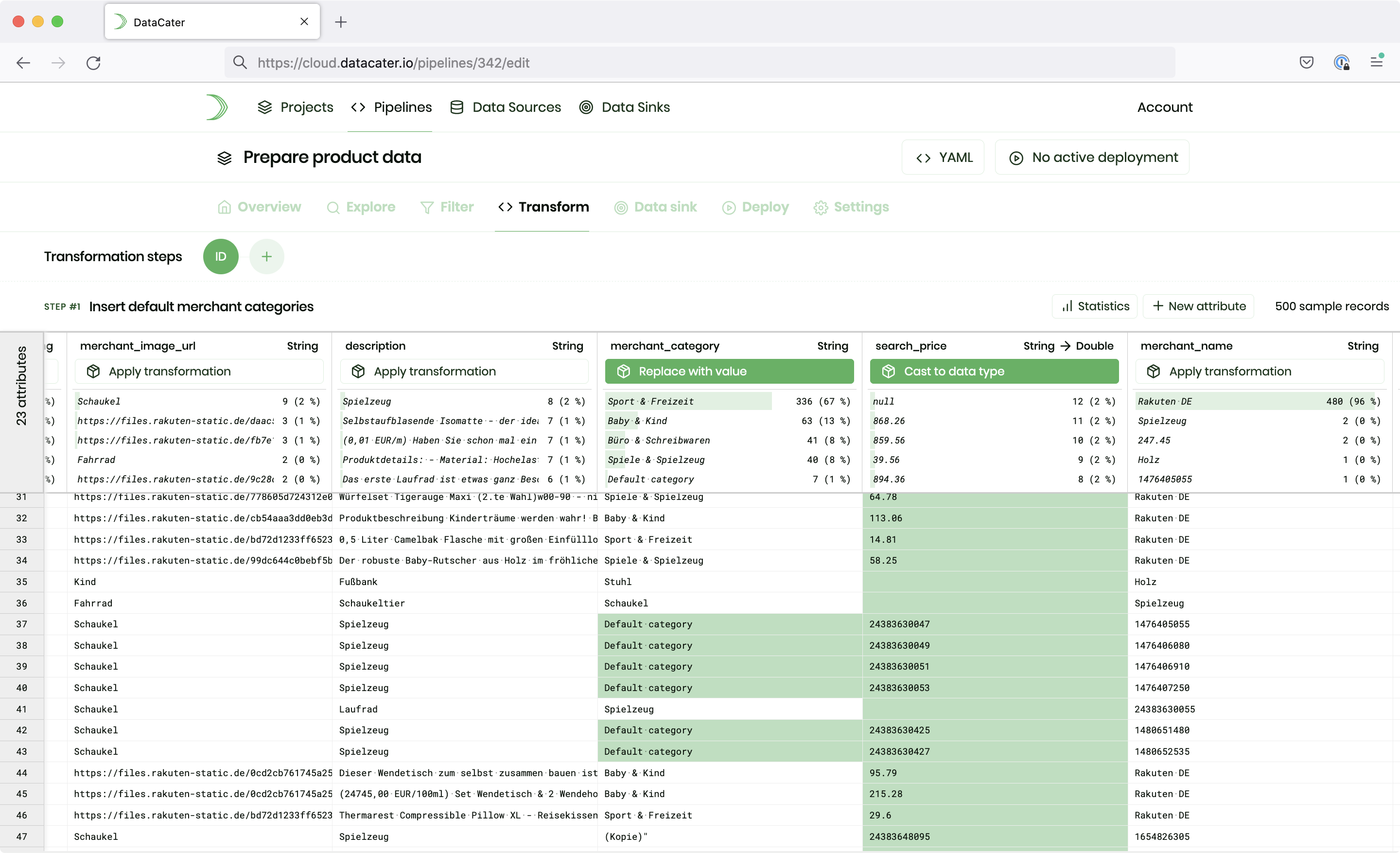
Transform data in real-time
The T in ETL stands for Transform. Streaming ETL
pipelines cannot only sync data between two data systems in real-time but also transform them on the way.
In streaming ETL pipelines, transformations are used to:
Filter data
By default, streaming ETL pipelines process all data from a
data source. Filters might be useful if only a subset of the
source data, for instance, only products of a specific category, are of interest for the downstream applications.
Clean data
Typically, streaming ETL pipelines consume raw data from a data
source and must clean the data on the way in preparation for
the downstream usage. Cleaning data might include performing
tasks, such as replacing missing values, normalizing attribute
values, or fixing typos in text values.
Change the schema of data
Most data sinks do not use the exact same schema as data
sources. ETL pipelines must take care of handling differences
in data types, attribute names, or the availability of attributes. To this end, they apply transformations that manipulate the schema of the data, such as casting data types, renaming attributes,
introducing new attributes, or removing attributes, while
streaming data from data sources to data sinks.
Enrich data
Oftentimes, raw data in data sources lack information that
needs to be added to the data before loading them into the data
sink. For instance, one might want to automatically enrich a
data set containing phone numbers with the cities of the area
codes. In such cases, streaming ETL pipelines can enrich data
with additional information while streaming them.