Under the Hood of DataCater
An introduction to the building blocks that make up DataCater, the platform for continuous data preparation.
An introduction to the building blocks that make up DataCater, the platform for continuous data preparation.
In a previous article, we gave a high-level introduction to the concepts behind DataCater. In this post, we intend to cover the architecture of DataCater from a more technical perspective. We explore the different building blocks that make up the DataCater platform, explain why we chose them, and discuss how they relate to each other.
Feel free to reach out to us in case of any open questions or remarks. We’d be happy to update this blog post with further information that is of interest to you.
DataCater is the complete platform for continuous data preparation. It provides efficient tools for building, managing, and operating streaming data pipelines, which stream data change events from data sources to data sinks in real time and transform them on the way. DataCater helps companies to strongly reduce the time spent on data preparation and allows analytical applications to always work with the most recent data.
Having multiple decades of combined experience in working with data, we identify two main flaws in today’s solutions for data preparation: (1) Data preparation requires a tremendous amount of time due to a large number of repetitive tasks, and (2) prepared data is rarely up to date because the execution of data pipelines is not automated.
We set out to address these problems and advance the state of data preparation. We had the following main objectives in mind while designing the architecture of DataCater:
It’s common wisdom in the data community that data experts spend the majority of their time on preparing data before being able to make actual use of them, a phenomenon often referred to as the 80/20 rule. To reduce the time spent on data preparation, we must make the development of data pipelines more efficient.
The status quo of building data pipelines is code-based. In multiple iterations, developers move from the first draft of a data pipeline to an implementation that sufficiently prepares the data for downstream usage. After each iteration, developers need to manually execute the current version of the data pipeline and check whether the output is as expected.
Going back and forth between writing code, running pipelines, and verifying results of the test runs is very time consuming. DataCater must break free from this model and allow the interactive development of data pipelines. While users build data pipelines with DataCater, it must instantly preview the impact of the data pipeline on real data from the data source, maximizing the transparency on applied transformations, such that the user can prepare data in one go.
Typically, data preparation is performed with ETL pipelines, which neither implement Change Data Capture nor achieve a fully automated execution. In each run, they need to process all data, regardless of whether they have changed since the last run. Since this approach puts a huge load on the data source, data pipelines are executed manually or recurringly, for instance, every night at 2 am. As a consequence, prepared data are seldomly in sync with raw data.
DataCater must minimize the delay in data replication. It must be able to extract data change events from data sources in real time and process these events instantly with a streaming data pipeline before publishing the prepared data to the data sink. This would allow downstream applications to always work with current data and, as a positive side effect, prevent wasting compute resources, because data pipelines only process data that have changed.
Given that a growing number of companies are moving their analytical applications to cloud platforms, DataCater must support a straightforward deployment on public, private, and hybrid clouds.
Since almost all cloud platforms are based on containers, both the DataCater platform as well as the data pipelines must be run as containers.
Besides, data pipelines must be implemented such that they can elastically scale their performance by launching additional (or removing) containers, a technique very common in container platforms. Autoscaling of data pipelines could be implemented by, for instance, the Horizontal Pod Autoscaler of Kubernetes, a container platform available on most clouds.
No data architecture is like the other. For that reason, DataCater must achieve great flexibility with regards to the supported data connectors and data transformations.
DataCater must not only offer data connectors for a plethora of different data stores, but also allow users to implement custom data connectors for data stores of their choice.
DataCater should not only support predefined transformation functions but enable users to develop custom transformation functions, a feature mandatory to cope with arbitrary requirements in data preparation.
It is very important that platforms processing data, such as DataCater, secure data from non-authorized access. This does not only include implementing a sophisticated authorization system in the user interface but also involves making sure that data pipelines cannot read data processed by other pipelines, even when they are executed on the same physical machine. This is especially important when allowing users to extend data pipelines with custom code.
Given that DataCater deploys data pipelines as containers it is guaranteed that data pipelines, even those that run custom user code, cannot break free from their execution environment and read data processed by a different data pipeline.
In the following sections, we discuss the building blocks that make up the DataCater platform. For an architectural overview, have a look at the following figure that sketches the main components of DataCater, which we discuss in more detail in the following sections.
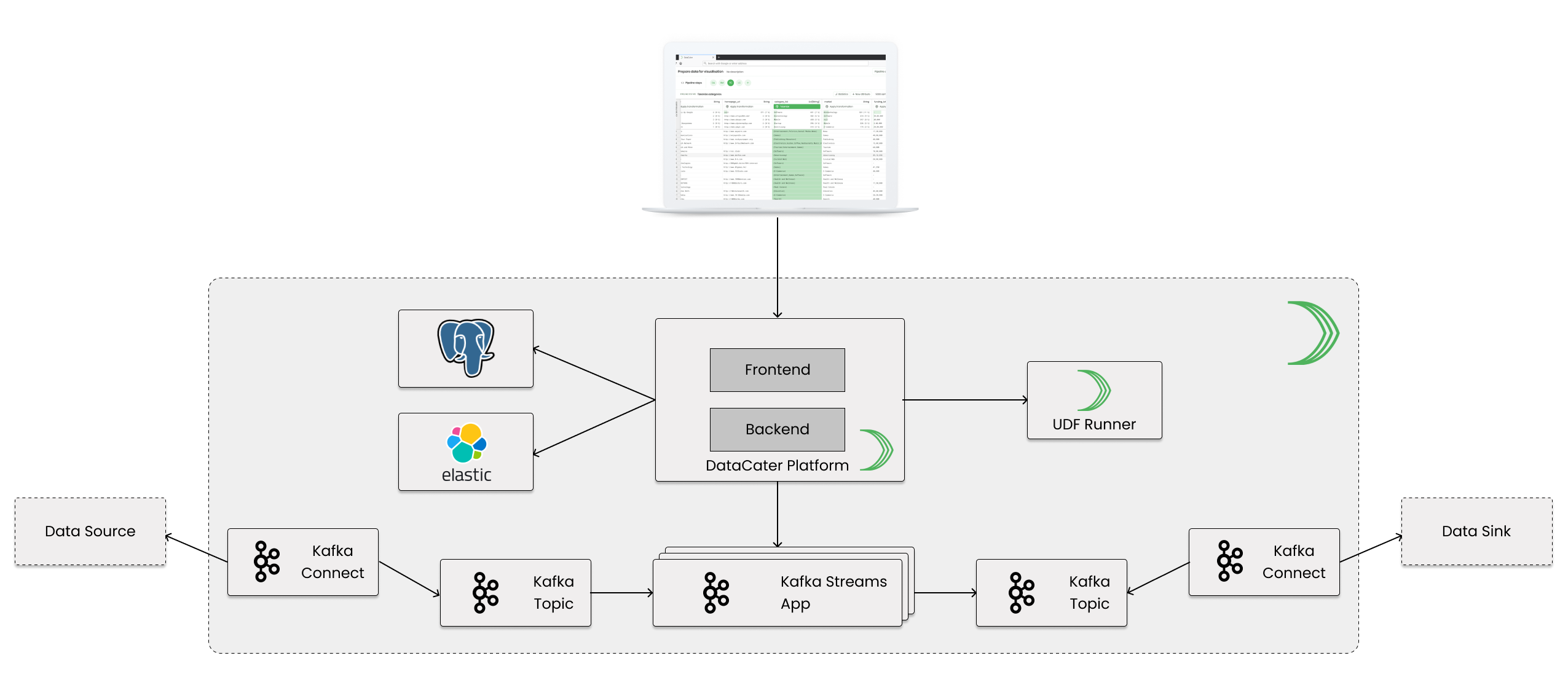
The DataCater Platform is the only service that users interact with. It consists of a frontend, implemented as a ReactJS application that is running in the browser of the user, and a backend implemented as a Scala Play application.
The frontend provides efficient tools for managing data pipelines, data sources, and data sinks. Users can use DataCater’s Pipeline Designer to interactively build streaming data pipelines, connecting data sinks with data sources, in their web browser.
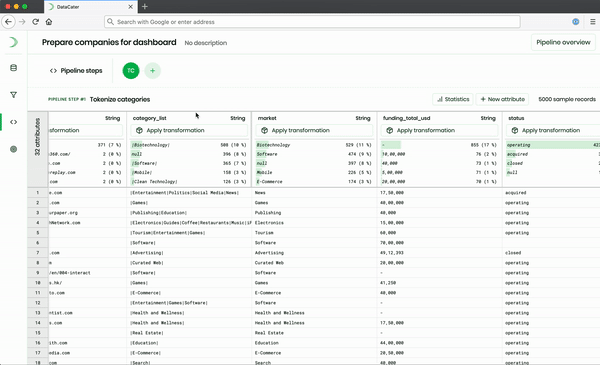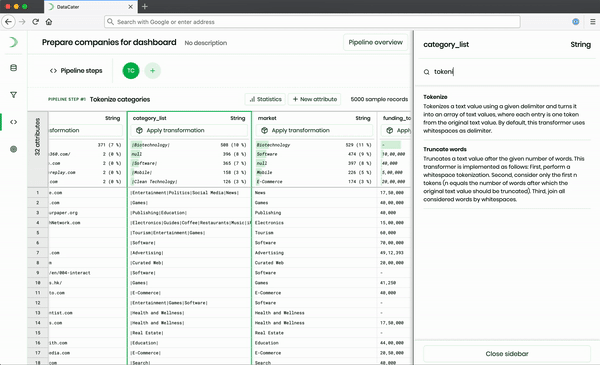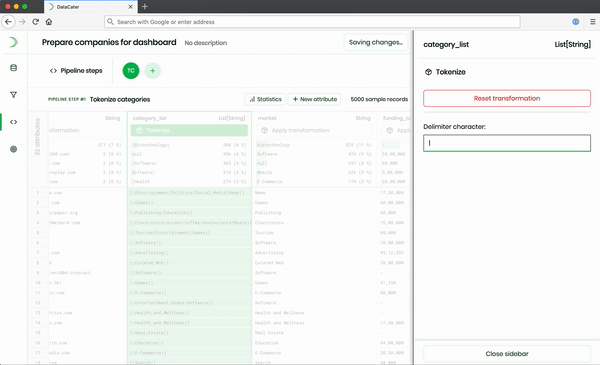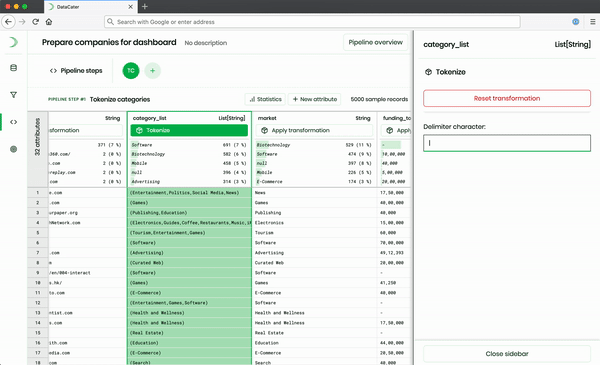
The Pipeline Designer, which is part of the frontend, offers an extensive repository of predefined transformation and filter functions, which can be combined to build arbitrary data pipelines. When applying transformations, the Pipeline Designer instantly previews their impact on sample data from the consumed data source. It does not only support predefined transformations but also allows users to develop custom transformations as Python functions. While predefined transformations can be simulated in the frontend, the Pipeline Designer needs to approach the backend for evaluating the impact of custom Python functions.
The backend offers different REST endpoints used by the frontend for retrieving and manipulating entities such as pipelines, data connectors, etc. The backend is responsible for compiling data pipelines built with Pipeline Designer to executable software code, which is packaged using Docker images. Furthermore, the backend takes care of tasks, such as deploying pipeline containers, orchestrating data connectors, interacting with third-party services, etc.
Internally, the backend uses PostgreSQL and Elasticsearch as data stores for structured and unstructured data, e.g., management of user accounts, storage of access rights, indexing of sample data, etc.
Both the frontend and the backend are served by the same container.
Technically, the backend itself could evaluate user-defined transformation functions for determining their impact on data as required by the Pipeline Designer. However, this would impose several security vulnerabilities, because we could never perfectly prevent user code from performing malicious operations possibly damaging the installation of DataCater or even bypassing DataCater’s authorization system securing data from non-authorized access.
As a consequence, all user-defined transformation functions are executed in a separate container, the UDF Runner service, which exposes a lightweight API that is called by the backend.
DataCater uses Apache Kafka as a fault-tolerant, scalable, and persistent storage system for data change events that were extracted from consumed data sources, like insertions of new records, updates of existing records, or deletions of records.
Kafka offers topics as a concept for separating different kinds of records (or events) from each other; similar to a table in a database system. For each data source, DataCater manages one Kafka topic, which holds all data change events from the data source.
As described in the following section, data pipelines consume raw data change events from the topic associated with the consumed data source, transform the data change events according to the pipeline definition, and publish the transformed data change events to another Kafka topic, which is associated with the data sink assigned to the data pipeline. In addition to the Kafka topics for data sources, DataCater manages one Kafka topic for each data sink.
By using Kafka for the storage of data change events, we can guarantee that no data are lost, even if a data pipeline is stopped for a certain period, as long as the Kafka brokers are still alive and the unavailability of the data pipeline is shorter than the retention period of Kafka (by default, we use a retention period of seven days after which events are automatically removed from Kafka topics).
DataCater compiles data pipelines built with the Pipeline Designer to optimized Kafka Streams applications, which consume data change events from the Kafka topic of the data source, apply the transformations and filters defined in the Pipeline Designer, and publish the transformed data to the Kafka topic of the data sink.
For each Kafka Streams application, i.e., each data pipeline, DataCater builds a distinct Docker image, which can be deployed as a container.
We chose Kafka Streams as the underlying stream processing framework because we already make use of the Kafka message broker and therefore would not need to introduce another dependency. Furthermore, Kafka Streams allows to elastically scale data processing by launching additional instances of the same Kafka Streams application. This enables the automatic scaling of data pipelines, especially when deployed on container platforms, such as Kubernetes.
Since data pipelines are isolated from each other and run in separate containers, we can directly evaluate user-defined transformations inside the pipelines’ containers without risking any security vulnerability.
So far we have discussed how DataCater can be used to interactively build optimized Kafka Streams applications, which consume data from one Kafka topic and publish transformed data to another Kafka topic. There is still one open question: How can we get data from an external data store into a certain Kafka topic and vice versa?
Kafka Connect is a service for reliably transferring data between external data systems and Kafka topics. It provides an API for both source and sink connectors.
Source connectors stream data from an external data store, e.g., a MySQL database system, into a Kafka topic.
Sink connectors stream data from a Kafka topic to an external data store, e.g., a Hive data warehouse.
DataCater automates the management of source and sink connectors using the REST API exposed by Kafka Connect. DataCater continuously monitors the health of the connectors and can notify users once a certain connector becomes unavailable.
Using Kafka Connect as the foundation for data connectors does not only make a large set of existing connectors available to DataCater but also enables users to develop custom data connectors.
In this article, we presented the architecture of DataCater, the platform for continuous data preparation. DataCater was built with the goal of saving time for data experts and fully automating the preparation of data.
We described the main objectives we had in mind while designing the architecture of DataCater. We also discussed the main building blocks of the DataCater platform and described how they fit together.
Are you interested in learning more about DataCater or seeing DataCater in action? We’d be happy to schedule a call with you.