Introducing Projects to DataCater
DataCater introduces projects as a collaborative means for data teams to prepare and integrate data collectively.
DataCater introduces projects as a collaborative means for data teams to prepare and integrate data collectively.
Collaboration on data was never more important than today.
Driven by the transformation of enterprises to data-driven organizations, modern data teams feature stakeholders from both business and engineering. While business analysts have profound domain knowledge about the data, engineers possess the technical skills to process data with code.
Data teams have a hard time collaborating because the different persona speak different languages: While people from the business units are used to tools like spreadsheet applications, engineers are most productive when implementing data requirements in programming languages such as Python.
DataCater aims to bridge the gap between business and engineering. It offers a unified approach to working with data pipelines that is accessible to both non-coding domain experts and engineers with programming expertise. While domain experts can use DataCater’s no-code pipeline designer to implement business rules without coding, engineers can implement custom requirements as Python-based user-defined transformation functions.
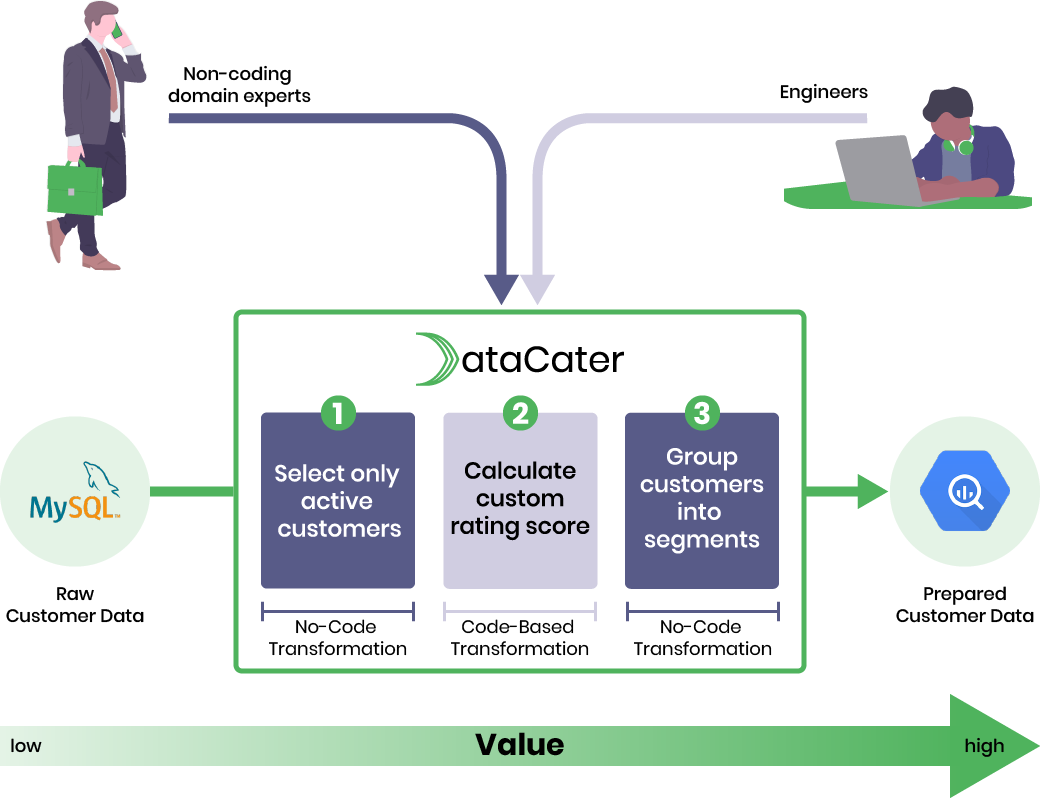
Today, we are happy to announce the support for project-based work in DataCater. We propose projects as a collaborative means that allows data teams to work together on all tasks related to data preparation and integration.
Projects allow users to share data sinks, data sources, and pipelines with colleagues and teammates. Instead of building up knowledge silos in private data pipelines, users can team up to implement business rules and data requirements collectively.
Combined with the capability of DataCater’s Pipeline Designer to preview transformation functions on sample data, projects allow, for instance, business users to interactively validate the code-based implementation of business rules provided by engineers.
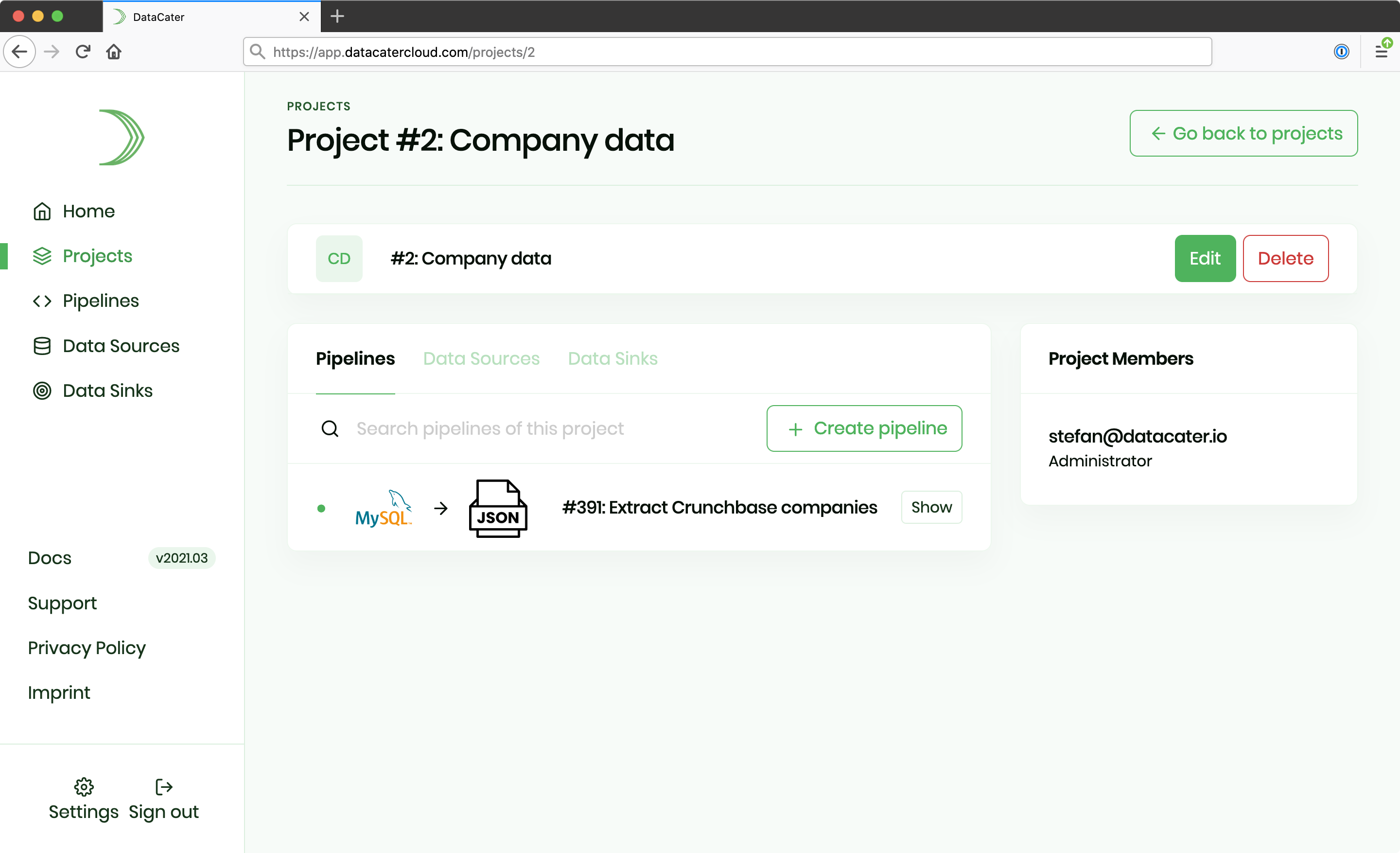
DataCater supports multiple user roles in projects:
Viewer: Viewers are project members, which get read-only access to all project resources. They can, for instance, preview pipelines, access the definition of transformations, or view pipeline logs, but cannot introduce any changes to resources.
Editor: In addition to the read permissions of Viewers, Editors can also manage resources. They can update transformations, create and start deployments, or change the configuration of data sources. However, editors cannot manage the project or delete project resources, e.g., pipelines.
Administrator: Administrators get unrestricted access to the project and all assigned resources. They can manage the project and, for instance, remove project members or update user roles. In addition to the permissions of Editors, they can also remove pipelines, data sinks, or data sources from the project.
User roles provide fine-granular control over which user can perform which actions in a project.
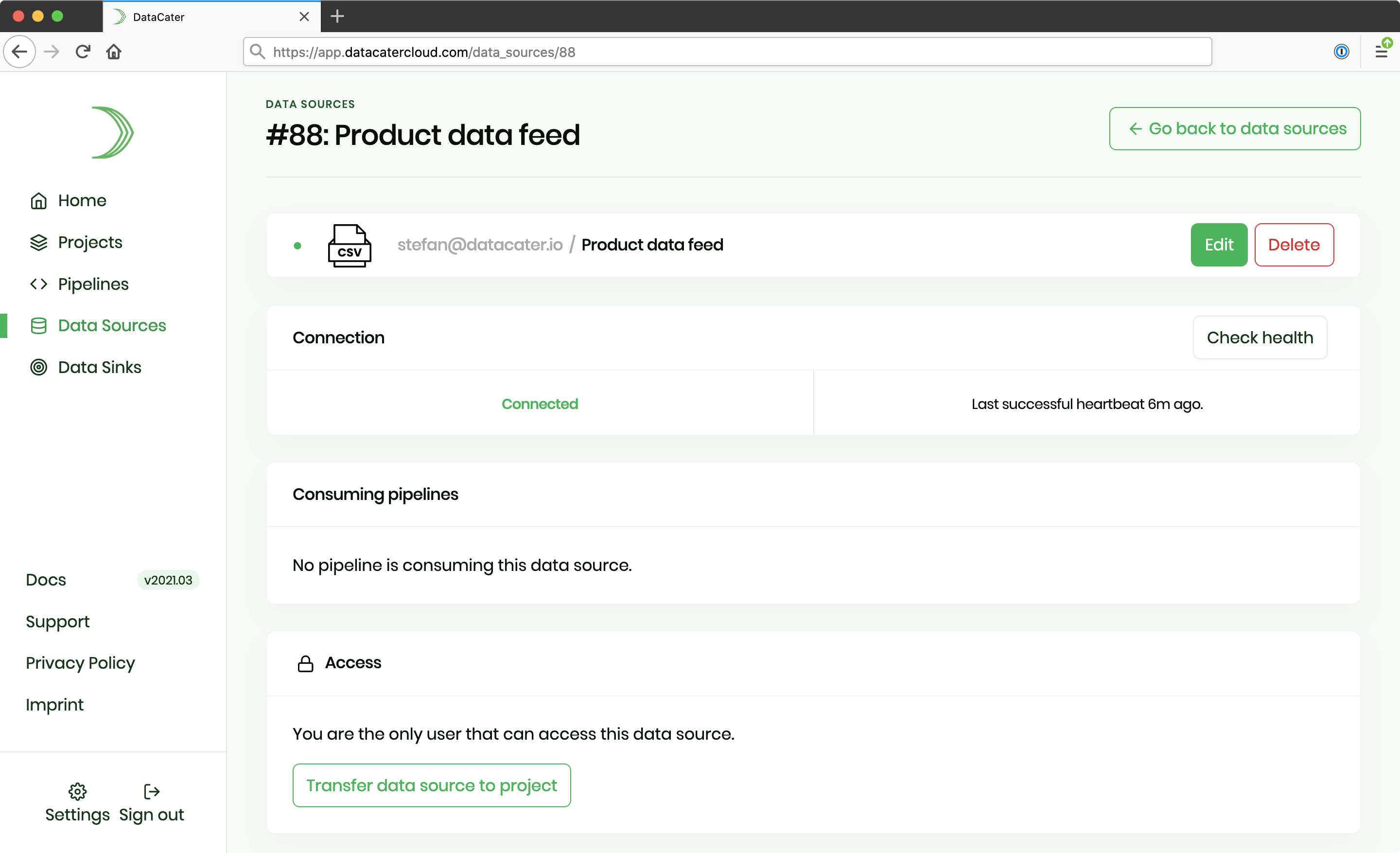
DataCater allows you to migrate your private resources to projects to enable collaboration with colleagues.
On the overview page of the respective resource, you can transfer your private resource to one of your projects. The following screenshot shows this for an exemplary data source.
Are you interested in learning more about DataCater? Feel free to reach out to us using the following form. We would be happy to talk about your use cases and show you DataCater in action.

We will get back to you as soon as possible.