Troubleshooting The Performance of Streaming Data Pipelines
Get to know two essential performance indicators: pipeline lag and sink connector lag.
Get to know two essential performance indicators: pipeline lag and sink connector lag.
When integrating distributed systems, lots of things might go wrong. Instead of hoping for the best, it’s better to be prepared for the worst and have tools at hand that help troubleshoot problems. This article introduces two essential performance indicators for streaming data pipelines: pipeline lag and sink connector lag.
Streaming data pipelines act as the glue between data systems. They stream data from a data source to a data sink, and may transform the data on the way.
The key advantage of streaming data pipelines over their batch-based counterpart is that they process data in real-time. Streaming data pipelines extract data source changes in real-time, often by implementing a technique called Change Data Capture, process them with a set of transformation functions, and publish the processed data to the data sink.
The data source connector is responsible for extracting events from the external data source system, such as a database, and publishes them to an internal log (we’re heavy users of Apache Kafka). The log is consumed by a streaming data pipeline, which might apply transformations to the data events and publishes the transformed events to another internal log, which is eventually consumed by the data sink connector. The data sink connector is responsible for publishing the transformed events to the external data sink.
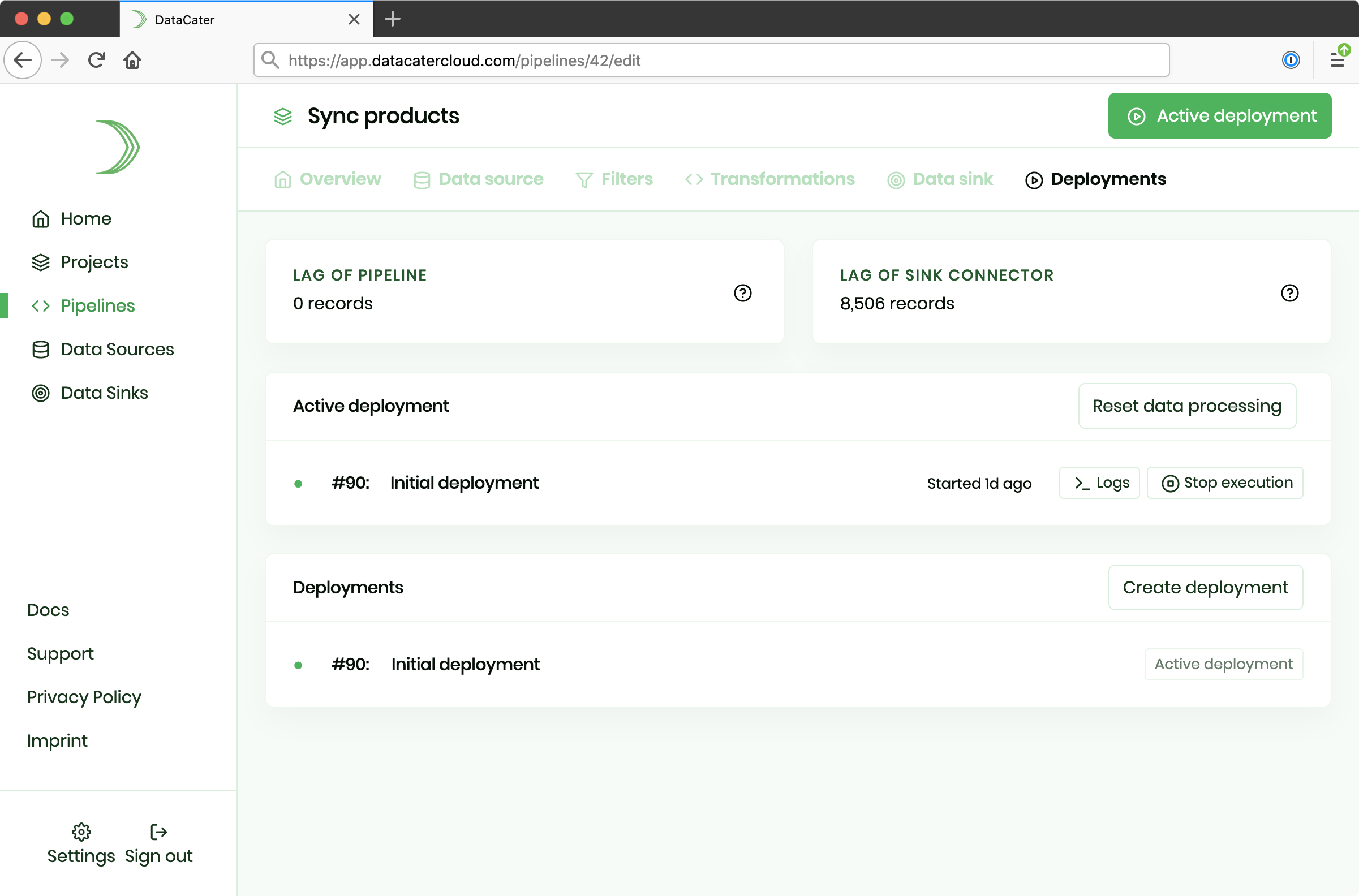
The pipeline lag equals the number of events that have been extracted by the data source connector but have not yet been processed by the streaming data pipeline.
The pipeline lag impacts the end-to-end latency of data events, i.e., the higher the pipeline lag the longer it takes for an event to be streamed from the data source to the data sink.
Especially growing pipeline lags are worrisome because they worsen the situation over time.
A high pipeline lag might have different root causes, typically boiling down to the situation where the data source connector produces events at a higher pace than they can be processed by the streaming data pipeline. An example might be a data source connector producing one change event every second and a pipeline stalling two seconds for every event.
DataCater implements streaming data pipelines with Apache Kafka Streams and can treat high pipeline lags by parallelizing the processing of events. Once the pipeline lag exceeds a certain threshold, which is unique to the use case, additional instances of the streaming data pipelines can be instantiated to accelerate the processing of events.
DataCater shows the current pipeline lag in the Deployments section of the Pipeline Designer.
The sink connector lag equals the number of events that have been processed by the streaming data pipeline but have not yet been published by the sink connector to the external data sink system.
Similar to the pipeline lag, the sink connector lag impacts the end-to-end latency of data events, i.e., the higher the sink connector lag the longer it takes for an event to be streamed from the data source to the data sink.
A high sink connector lag is typically caused by the data source system producing events at a higher pace than the data sink system can consume them.
DataCater implements source and sink connectors with Apache Kafka Connect. Depending on the root cause of the high sink connector lag and the type of the data sink system, DataCater can treat high sink connector lags with, for instance, parallelizing the publishing of data to the data sink system with multiple threads or batching multiple to-be-published data events in the same request.
DataCater shows the current sink connector lag in the Deployments section of the Pipeline Designer.
This article introduced two essential performance indicators for streaming data pipelines: pipeline lag and sink connector lag. High lags increase the end-to-end latency of streaming data pipelines and should be avoided. Especially growing lags are concerning and should be resolved as soon as possible.
DataCater helps in troubleshooting the performance of streaming data pipelines by presenting the current pipeline lag and the current sink connector lag in the Deployments section of the Pipeline Designer.
Get started with DataCater, for free
The real-time ETL platform for data and dev teams. Benefit from the power of event streaming without having to handle its complexity.