Declarative Data Pipelines
Declarative data pipelines allow for more reliable, resilient, and reproducible deployments and faster iterations in development.
Declarative data pipelines allow for more reliable, resilient, and reproducible deployments and faster iterations in development.
As stated in CNCF’s definition of cloud-native technologies, declarative APIs are a cornerstone of cloud-native technology. Among APIs, we also have tools like Hashicorp Terraform, AWS CloudFormation, Kubernetes Manifests, and others that commoditize Infrastructure as Code and enable developers to manage their infrastructure in a declarative manner.
A declarative approach allows for more reliable, resilient, and reproducible deployments and faster iterations in development. To allow the declarative definition of data pipelines, the underlying platform needs to fulfill a couple of prerequisites.
A common pattern in cloud-native environments is the outsourcing of the application state, e.g. moving session affinity to load balancers, implementing cache management with key-value stores, etc. State-managing technologies are consumed as services, which are declared as dependencies and either configured during runtime or at deployment time.
"Unlock declarative data pipelines by outsourcing state management to an event streaming system like Apache Kafka."
To enable declarative descriptions of data pipelines, we require services to keep some state and connect individual data pipelines to these. Each data pipeline requires the ability to outsource:
Questions 2 and 3 are easily answered by an orchestration system like Kubernetes. Connections to data sources and sinks can be defined through a combination of ConfigMaps and Secrets, which can be referenced at container startup time. New data pipelines might be configured to use a certain Secret managed by the operator deploying the pipeline.
Container orchestration systems provide means to declare how many resources a given application requires. Such ResourceRequests can be used to schedule a data pipeline.
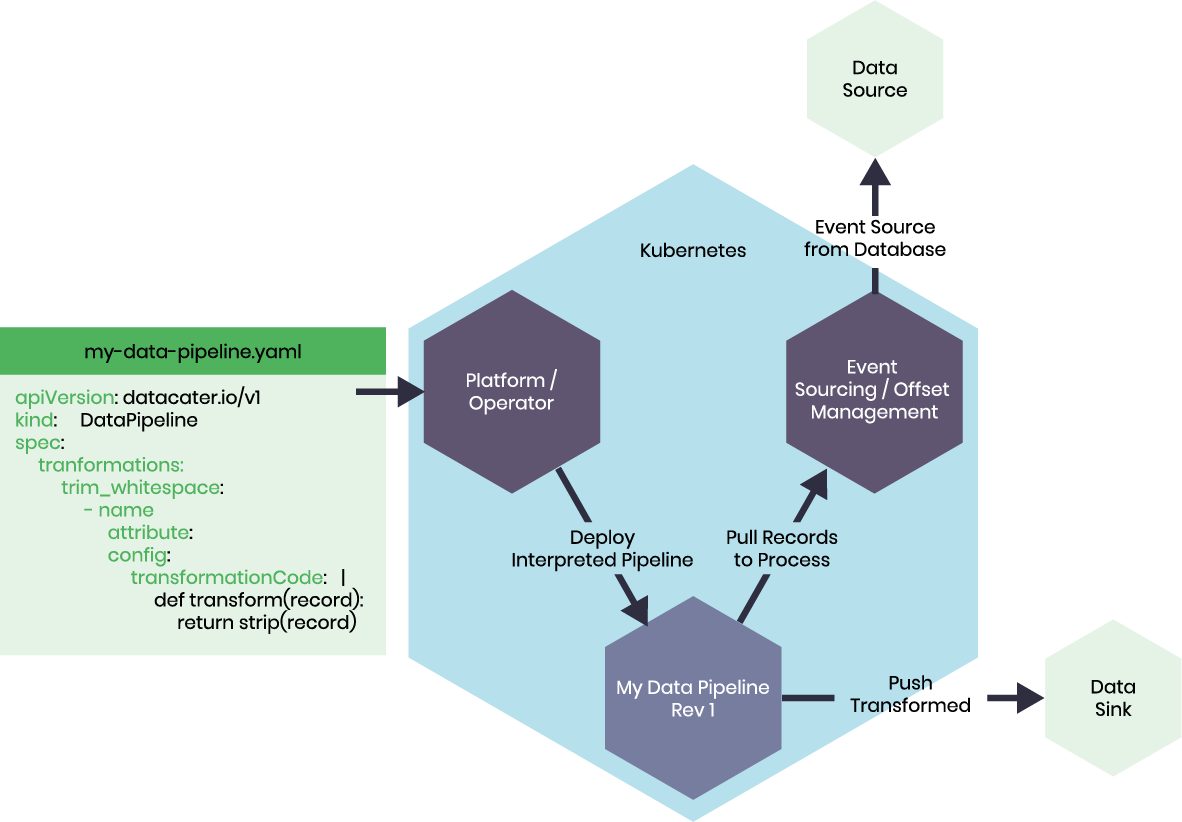
Which data has already been processed? DataCater uses Apache Kafka to keep track of records processed by committing offsets. Event-sourcing systems source events from data stores and can retain the data for a requested period of time in their local storage. Sourced events can be emitted or polled by data pipelines to apply transformations and load the processed data into target data sinks.
Therefore, an event-sourcing system such as Apache Kafka Connect is crucial for modern cloud-native data pipelines. Having a service tracking what data has processed by which consumer unlocks the potential for having a declarative approach to data pipelines.
With state management provided by a platform with the above components, we can define Data Pipelines as a set of three components: data sources, filters and transformations, and data sinks. The following figure illustrates a cloud-native data pipeline:
Want to learn more about the concepts behind cloud-native data pipelines? Download our technical white paper for free!
