Building Real-Time ETL Pipelines with Apache Kafka
Learn how to use Apache Kafka to implement streaming ETL.
Learn how to use Apache Kafka to implement streaming ETL.
Whether you’re a data engineer, a data scientist, a software developer, or someone else working in the field of software and data - it’s very likely that you have implemented an ETL pipeline before.
ETL stands for Extract, Transform, and Load. These three steps are applied to move data from one datastore to another one. First, data are extracted from a data source. Second, data are transformed in preparation for the data sink. Third, data are loaded into a data sink. Examples are moving data from a transactional database system to a data warehouse or syncing a cloud storage with an API.
In this article, we provide an introduction to building real-time ETL pipelines with Apache Kafka, Apache Kafka Connect, and Apache Kafka Streams.
We have instant access to most information at any time (Thank you, Google!) and can get our groceries delivered in under 10 minutes. Why are we still forced to work with outdated data?
Traditional batch ETL pipelines perform heavy bulk loads for data extraction. At each run, they need to extract and process all data from the consumed data source regardless of which data have changed since the last run. Batch pipelines cannot be scheduled too often because they put a high load on all involved systems, especially the consumed data sources, leaving the data sinks outdated most of the time.
Real-time (or streaming) ETL pipelines apply change data capture (CDC) for data extraction. They are able to detect changes (INSERTs, UPDATEs, DELETEs, and sometimes even schema modifications) in data sources and process them - event by event - in real-time. Depending on the type of the data source, different mechanisms and tools might be employed for capturing events. For instance, if your data pipelines are consuming database systems, you might want to have a look at tools, like Debezium, which are capturing changes from replication logs.
The benefits of real-time ETL pipelines are manifold.
The most obvious advantage is that they can sync changes from data sources to data sinks in real-time, allowing data consumers to always work with fresh data in dashboards, reporting, and analytical applications.
When being combined with CDC connectors, real-time ETL pipelines consume
and process only relevant changes, which reduces the load on data sources strongly.
Reading from a replication log file is much more efficient than
performing a SELECT * FROM query on a database for data extraction.
Nowadays, most companies employ their data architecture on a cloud platform. Another advantage of real-time ETL pipelines is that they have much more predictable and continuous workload patterns than batch jobs. This is not only beneficial for applying elastic scaling as available in technologies, like Kubernetes, but also helps to reduce cost via usage commitments (cloud vendors typically offer discounts if you commit to using resources for a certain period of time).
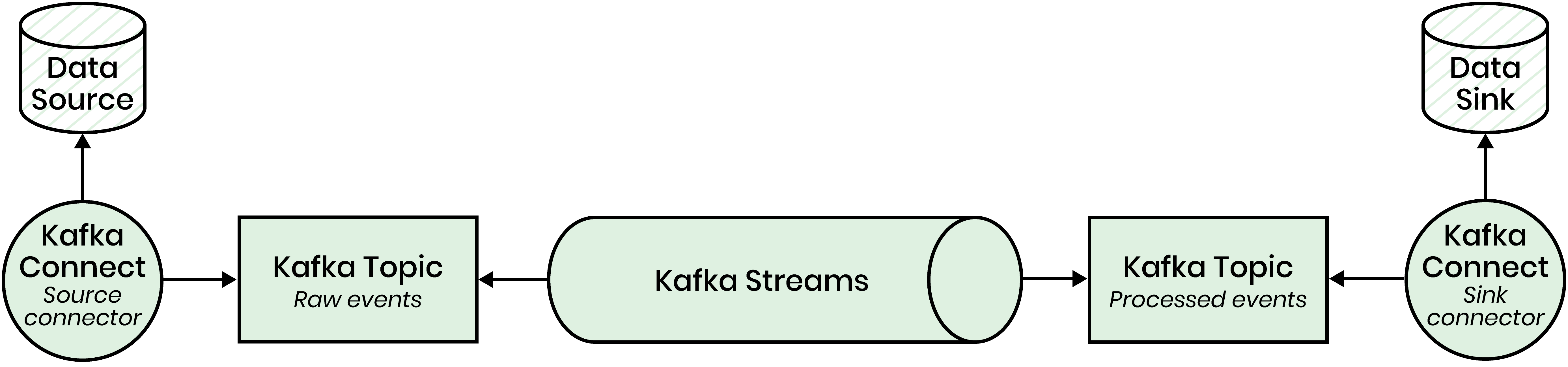
Apache Kafka is an open-source distributed event streaming platform offering a message broker (or distributed log) as its core product. Over the last couple of years, many great supplementary products have emerged from the community, like Apache Kafka Connect for integrating Kafka with third-party data systems or Apache Kafka Streams for building stream-processing applications on top of Apache Kafka. These products - Kafka, Kafka Connect, and Kafka Streams - make up great building blocks for developing real-time ETL pipelines.
At the core, Apache Kafka is a distributed log that organizes messages in topics. Each message consists of a key, a value, and a timestamp, and is identified by an offset that is related to its position in the topic (partition). In the architecture of a real-time ETL platform, we might use Apache Kafka to store data change events captured from data sources - both in a raw version, before applying any transformations, and a prepared (or processed) version, after applying transformations.
Using Apache Kafka Streams, we can build sophisticated stream-processing
applications that literally stream messages between different Kafka
topics and perform operations, such as map(), filter(), join(), or
aggregate(), on the way. Kafka Streams applications can be developed
in Java or Scala and are a perfect fit for a cloud-native deployment as containers
because they are stateless and horizontally scalable out of the box.
When deploying Kafka Streams apps on Kubernetes, we can utilise its Horizontal Pod Autoscaler to elastically adapt the resource consumption.
You might want to have a look at recent cloud-native alternatives to
Kafka Streams, such
as Quarkus, too.
Thanks to Kafka and Kafka Streams, we are able to store and process change events. But how do we integrate our real-time ETL platform with external data systems, such as a database system, a data warehouse, or an HTTP API? Apache Kafka Connect to the rescue! Kafka Connect is a Java-based framework for developing source and sink connectors. Source connectors extract change events from an external data system and publish them to a Kafka topic - in our case, the Kafka topic holding the raw change events. Sink connectors consume a Kafka topic - in our case, the Kafka topic holding the transformed change events - and publish these events to an external data sink. The open-source community has published a plethora of Kafka Connect connectors for integrating database systems, HTTP APIs, data warehouses, etc. You can even use existing Apache Camel connectors in Kafka Connect.
The following figure illustrates how these different components work together to accomplish real-time ETL:
This article gave an overview of how to combine the different products of the Apache Kafka ecosystem for building real-time ETL pipelines.
The open-source community provides most essentials for getting up and running. You can use open-source Kafka Connect connectors, like Debezium, for integrating Kafka with external systems, implement transformations in Kafka Streams, or even implement operations spanning multiple rows, such as joins or aggregations, with Kafka.
