5-Minute Introduction To Streaming Data Pipelines
Everything you need to know about the concepts of streaming data pipelines.
Everything you need to know about the concepts of streaming data pipelines.
Streaming data pipelines are the connecting pieces in a real-time data architecture. In general, they move data from data sources to data sinks and may process (or transform) the data on the way.

Streaming data pipelines are continuously executed and process event by event, keeping data sinks always in sync with data sources. In contrast, batch data pipelines sync entire data sets in one go and are executed less often.
Let’s assume you want to extract data from a transactional database system, like MySQL, and load them into a cloud data warehouse, like BigQuery, for analytics. Before loading the data into the warehouse, you would like to remove sensitive information with a couple of GDPR transformations. You could implement this use case with a streaming data pipeline, which employs a change data capture connector for consuming change events from the MySQL database system, applies GDPR transformations to the data on the fly, and loads the transformed data into BigQuery. The streaming data pipeline would enable your analytics use cases to have access to fresh data at any time and provide the best decision support to your business.

Becoming more concrete, streaming data pipelines are composed of different building blocks and technologies.
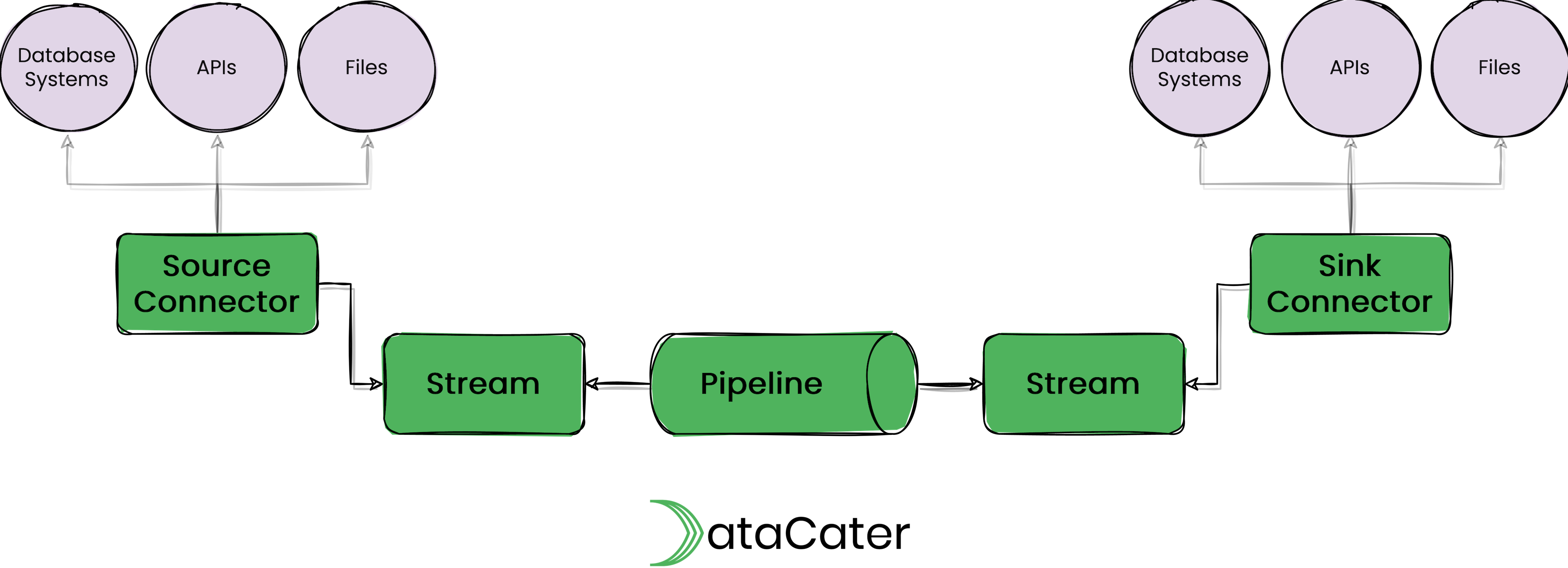
Streams
Streams are (partitioned) sequences of events (or messages). Typically, streams preserve the order of the events, at least within a specific partition.
Streams can be implemented with technologies, such as Apache Kafka®, Redpanda, Amazon Kinesis, or Google Cloud Pub/Sub.
Pipelines
Pipelines consume events from one (input) stream, process the events, and publish the processed events to another (output) stream.
For event processing, pipelines can apply filters, transformations, joins, aggregations, and other functions to the events.
Pipelines can be implemented with technologies, such as Kafka Streams, ksqlDB, or Apache Flink.
Connectors
Connectors take care of integrating streams with external data systems. They can be divided into source and sink connectors. Source connectors extract events from an external system, e.g., a MySQL table, and publish them to a stream. Sink connectors consume events from a stream and publish them to an external system, e.g., a BigQuery table.
Connectors can be implemented with technologies, such as Kafka Connect or Estuary.
Most data sets are continuously in motion. Online shops do not take a break between 6 pm and 10 am. Banks process transactions around the clock. Websites are accessible 24/7. Why do we still build data products, e.g., dashboards, product catalogs, or analytical applications, which work with outdated data?
In the past, implementing data pipelines as bulk imports (or batch loads) has been technologically the preferred solution despite the limited value provided to the business. With the rise of event streaming, implementing data pipelines as real-time data flows becomes feasible and allows businesses to use their data in the most natural way.
Across all industries, companies are morphing into data-driven organizations. They drive their operations and decision making with data and software. Data must have a high quality in order to maximize the received outcome. Freshness is certainly an important trait of high-quality data.
Streaming data pipelines ensure that businesses have access to fresh data at any time and empower decision makers with up-to-date information. One could even make the claim that having access to real-time information is a crucial prerequisite for a successful transformation to a data-driven organization.
By continuously streaming data change events, streaming data pipelines provide much more predictable and flat workload patterns than batch data pipelines. Such workloads are highly beneficial for cost and resource efficiency, since you don’t have to buy infrastructure for peak loads (on-prem) or heavily rely on on-demand instances (cloud), but can make use of smaller clusters (on-prem) or resource commitments (cloud).
Streaming data pipelines are a very promising technology for implementing data flows. Despite the recent technological advances, they are not yet accessible to the majority of the data and developer teams. Many of such technologies require users to understand highly-technical details and become experts in distributed computing to employ their first streaming solutions. A lot of companies, us being one of them, are currently working on products to overcome that hurdle.
At DataCater, we build a real-time data pipeline platform based on Apache Kafka, Apache Kafka Connect, and Apache Kafka Streams. Got 10 minutes to spare? Sign up for our free trial and build your first streaming data pipeline without having to set up and maintain the underlying technologies.
Get started with DataCater, for free
The real-time ETL platform for data and dev teams. Benefit from the power of event streaming without having to handle its complexity.