How DataCater helps AX Semantics’ Clients with Data Enrichment
Learn how the streaming data platform DataCater enables the clients of AX Semantics to enrich their data in real-time.
Learn how the streaming data platform DataCater enables the clients of AX Semantics to enrich their data in real-time.
This article is a blog post by Andreas Zeitler, project manager at AX Semantics.
We at AX Semantics absolutely love the possibilities DataCater gives our customers. In an effort to equip our content automation clients with even better tools, we started an experiment a few months ago: We wanted to see whether we can create structured data from an apparently unstructured input using DataCater’s transformation capabilities. This would help customers who don’t have good data sets to get started more quickly and improve their onboarding experience.
We witnessed that DataCater is a powerful tool for manipulating data off our platform. DataCater empowers our clients to provide better data, and therefore enables AX Semantics to work with high-quality data structures. This way, using AX NLG Cloud features like the Histogram, a statistical analysis tool, become readily available. Extending or enriching data helps content teams to be more self-sufficient, and they are able to deliver better texts faster.
Content automation projects benefit from having a lot of structured data available about, for example, products and all of their individual properties. As explained above, we sometimes have minimal or no data available. That often leads to the problem that writers need to figure out how to “add”, or enrich, data themselves by contextualizing existing data, either from a running text or in some other way. For instance, all products that are made from steel or iron might be considered “sturdy”. Similarly, all products made from aluminum are “lightweight”. It becomes a chore when writers have to do this for every single word they find in a huge chunk of data.
For our approach, we decided to explore the following possibilities:
Note: The data we used was drawn from a CSV file. We narrowed down the data source to one domain only, because ParseHub requires a special parse workflow for each domain.
In our case, the spreadsheet had an id, and a title column. To make life a little bit easier for our clients on the AX Semantics natural text generation platform, we renamed these columns to uid and name. Therefore, each product is being displayed with its id, and the title column is shown as its name directly on the AX NLG Cloud.
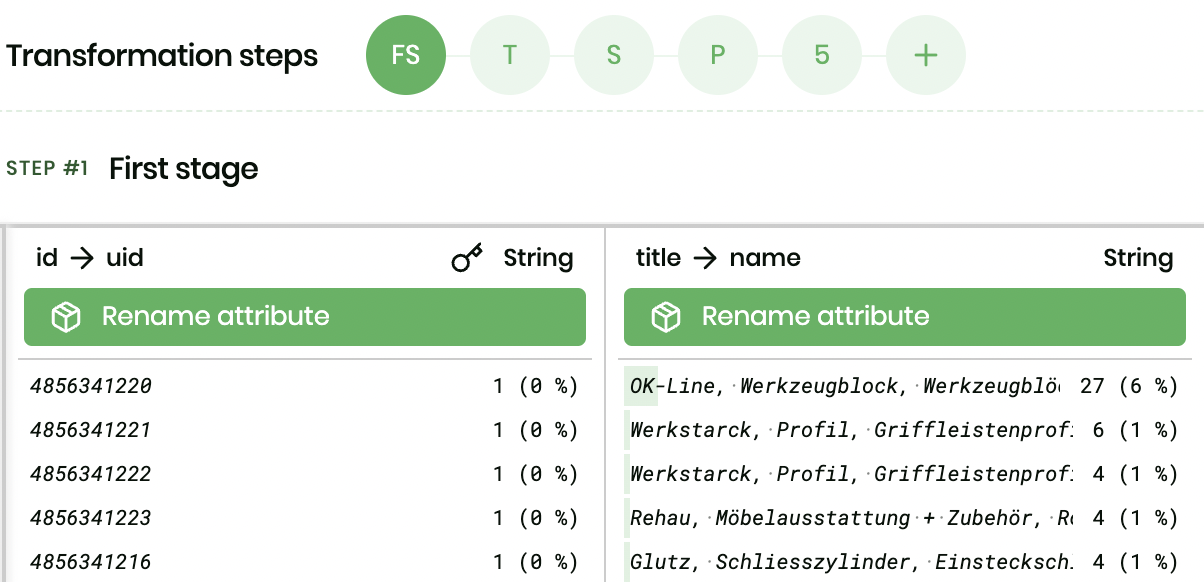
Our DataCater pipeline features five transformation steps in total. The transformations range from simple no-code transformations, like renaming columns or tokenizing strings, to more complex Python transformations.
We used the TAGS column from the original data set to build multiple additional columns. The data contained here is delimited with a comma (,) and separated with a = between key and value. But there doesn’t seem to be a strict rule for the data.
Sometimes, boolean values come as Ja, ja, or Nein. Other times it’s true and false. With DataCater, we can write a simple Python function to normalize these different notations.

Additionally, we separate the most commonly used “tags” into their own column, with a custom Python transform.
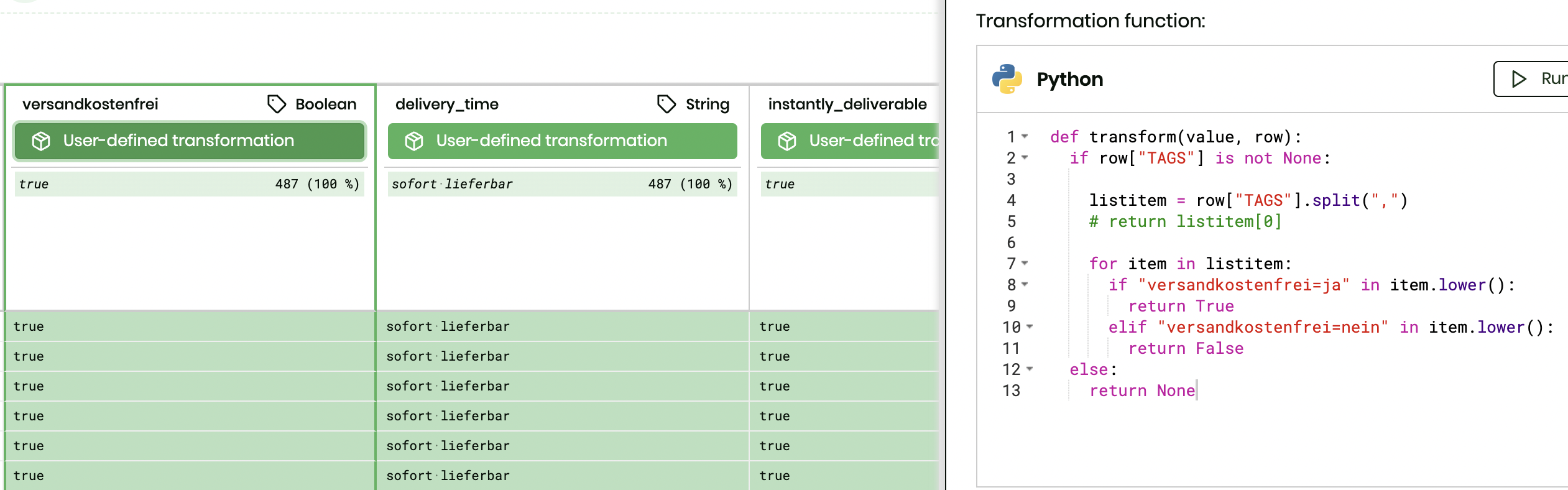
Note: It does make a difference to return None in case there is no match. If the script encounters an error, the entire row will be skipped before being sent to AX Semantics.
For the remaining tags we create a JSON-formatted output. We also remove the common tags.
Note that the bright green cells have a None value. It’s possible to simply return an empty {} also, but it seemed cleaner to do it this way:

The obvious upside of doing this is that writers are now able to use the Analyze feature on the AX Semantics platform for this kind of data:
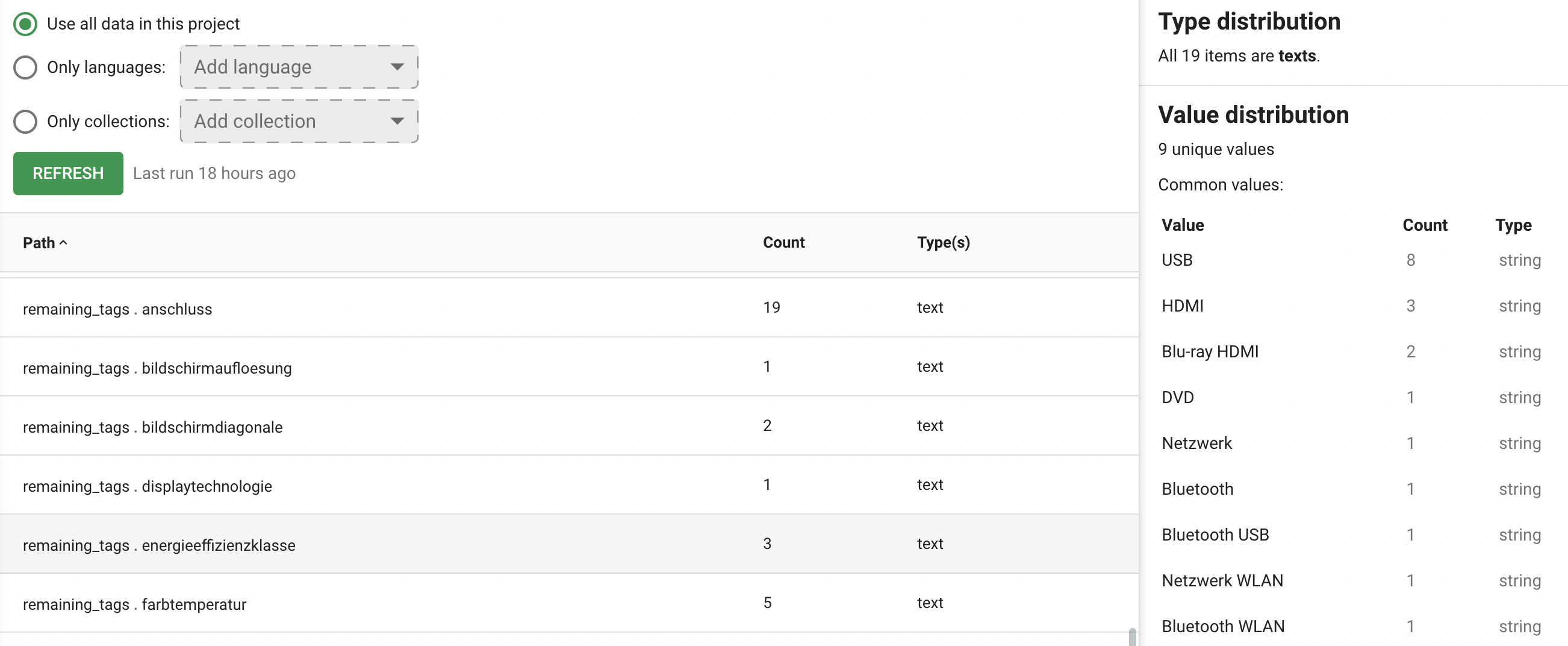
Also, it is a plus to offload some of these mundane manipulation tasks onto a platform that is made specifically for this kind of work.
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python. It’s designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems.
In the next attempt that still uses already available data, we used spaCy to process a “description” column in order to extract existing data. Some of our customers, with insufficient data, might still be able to give us an export of their website texts. This means we could use a tool to process these texts to turn them into data fields.
The out-of-the-box results with spaCy were a little so and so, to be frank. Without any modification with regards to data classification, rule-based matching, linguistic features, the extracted data wasn’t as consistent as we would have liked. The feedback that we got, however, suggests that doing it this way offers potential for users of our text generation platform. It gives more consistent results, than writing lengthy and complicated Regex rules – besides all engineering related challenges ahead.
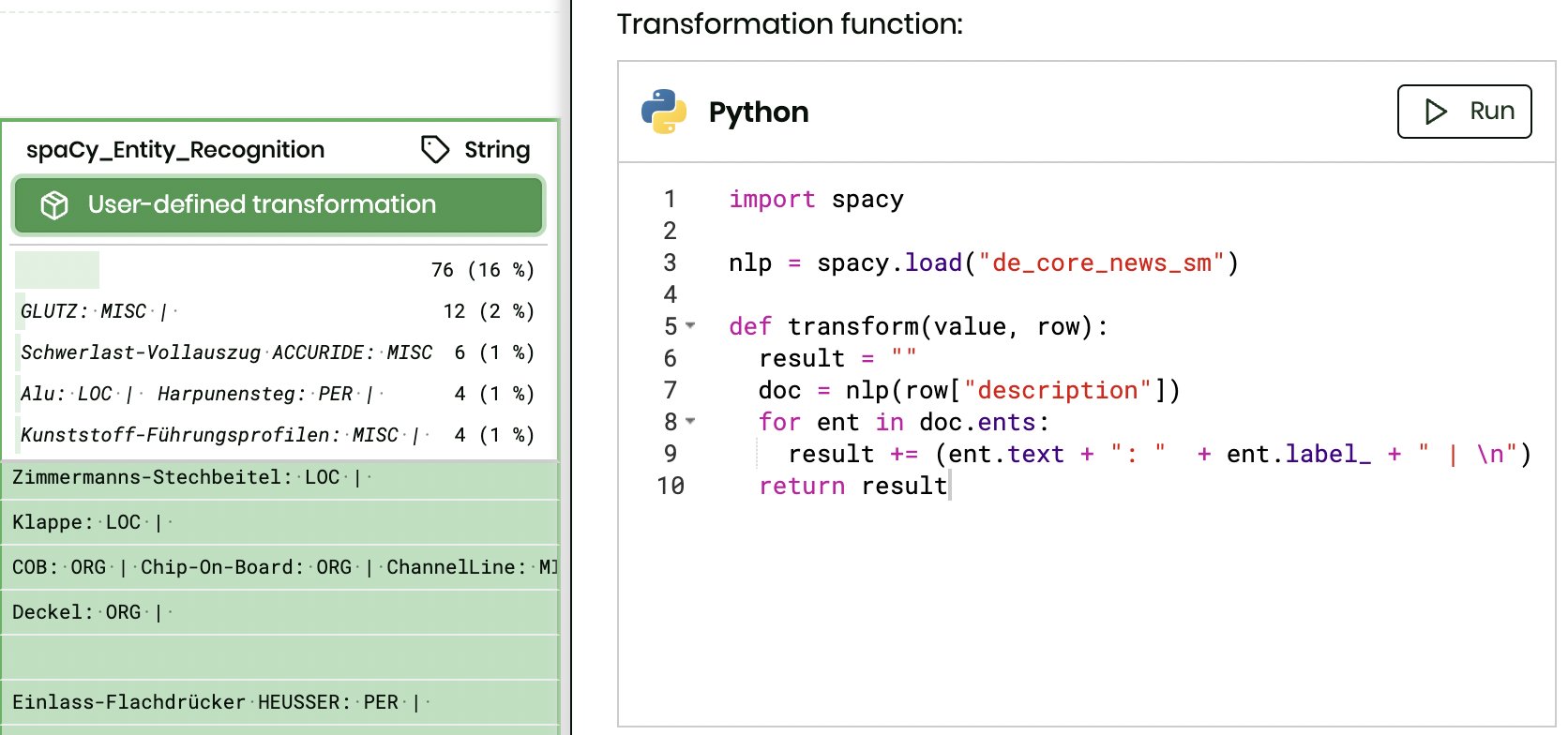
Note: We did not put a major effort into output formatting. As suggested above, returning a JSON-formatted result would make the output more accessible on the AX NLG Cloud.
{
"description": "Aktive Zentrierspitze für aktives Schneiden in Beton. Langlebiges Hartmetall. Gute Lebensdauer/Widerstandsfähigkeit. Verschleiß-Indikator. 4-spiraliges Turbo Design. Patentiertes 4-spiraliges Design, um das Bohrmehl effizient abzutransportieren. 2-Schneider, AWB Löten und Härten. Durchmesser optimierte Löt- und Härtungstechnologie, um die Robustheit des Bohrers zu steigern und die Vibration während des Bohrens zu senken. Verzahntes Hartmetall . Leitet den Staub direkt in die Spirale um eine Verstopfung durch Bohrmehl am Boden des Bohrloches zu verhindern. Die Sichtbarkeit des Verschleiß-Indikators gibt eine Orientierung hinsichtlich der Toleranz, um Dübel setzen zu können. Geeignet für Mauerwerk, Beton und armierten Beton. Passend zu allen Bohrhämmern mit SDS-plus-Aufnahme. 1er-Pack. 20 x 150 x 200 mm.",
"spaCy_Entity_Recognition": "Aktive Zentrierspitze: MISC | \nBeton: LOC | \nLanglebiges: LOC | \nAWB: ORG | \nBohrers: ORG | \nBohrmehl: PER | \nDübel: PER | \n"
}
spaCy allows us to process longer texts automatically. Right from the get-go the results weren’t great, but with a little bit of tweaking, we reached passable results that our writers are happy with. We’re looking into putting more effort into this approach.
In the last experiment we used a web scraping tool with a graphical frontend named ParseHub. The advantage of using a graphical tool is that writers, who aren’t technically as savvy as programmers, are still able to create their own workflows within a few clicks.
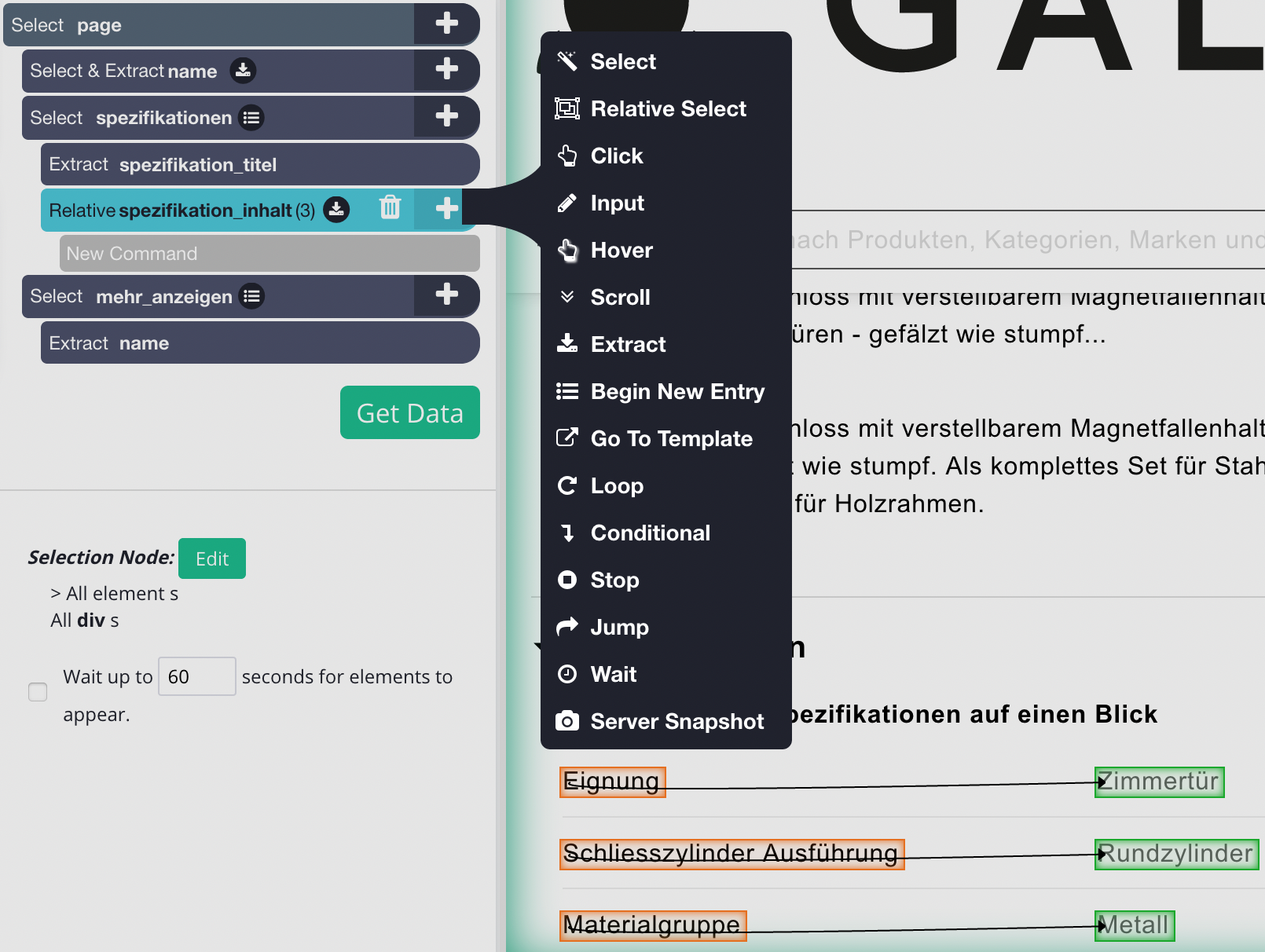
Essentially ParseHub allows users to select website elements which it turns into data fields. The tool offers various ways to interact with a website. Shown here is a so-called relative selection. It allows the creation of something like a key-value pair easily.
Selecting multiple elements is also pretty straight forward. The tool we tested is able to create a better (CSS) selection pattern, when more elements are selected, for example. Here we only selected “Eignung” and “Schliesszylinder Ausführung” to also select “Materialgruppe” and everything below it. Obviously, the relative selection carries on through to all the sibling entries.
{
"parseHub_pickup": "Number of tries: 1 :: {\n \"Produktname\": \"Hartmetall Hammerbohrer 20 mm\"\n}",
}
We discovered one major downside for us that practically makes ParseHub less feasible for the specific use case we were testing. That’s because we used a static CSV file as our input. This means that every time we changed something in the ParseHub workflow, we needed to run through the entire file again from top to bottom to see the changes. This is tedious, and wouldn’t be necessary if we had some sort of streaming input, where products are processed individually as each and every product changes.
As a result of our three experiment areas we found significant potential that would enhance the AX NLG Cloud experience. We were able to solve some of the hard tasks, with regards to enriching and extending the data, of our customers using DataCater. We’re very happy with the results so far, and continue exploring further improvements to the workflows we have ideated. Using DataCater made us discover many opportunities in cases where we wouldn’t be able to even get a text project started, because of either a complete unavailability of data, or a very poor data quality. This proof-of-concept work helped us to get much closer to fulfilling one of our customer segments’ dreams, and we are thankful for all the support we got from the DataCater team.
Get started with DataCater, for free
The real-time ETL platform for data and dev teams. Benefit from the power of event streaming without having to handle its complexity.