Data Streaming with Python
We compare three different tools for streaming data with Apache Kafka and Python: kafka-python, Faust, and DataCater.
We compare three different tools for streaming data with Apache Kafka and Python: kafka-python, Faust, and DataCater.
Data streaming is a data technology that allows continuous streams and flows of data from one end to another. One example of data streaming is extracting unstructured log events from web services, transforming them into a structured format, and eventually pushing them to another system. Popular open-source technologies for persisting event data are Apache Kafka or Apache Pulsar. While they started off as a pure persistence layer for data events, offering only low-level consumer and producer APIs to users, they later added high-level APIs for processing data events as well. For instance, Apache Kafka offers Kafka Streams and Apache Pulsar provides Pulsar Functions.
Although some of these tools support high-level programming languages such as Python and Go, JVM-based languages, like Java or Scala, are the most prevalent choice for stream processing today. For instance, user-defined functions in ksqlDB need to be implemented in Java.
So far, the data streaming community neglected the support for Python, despite it being the most used programming language in the industry, especially among data people. The vast majority of today’s data engineers and scientists prefer working with Python for the following reasons:
In this article, I provide a brief introduction to the data streaming technology Apache Kafka, which can be considered as the industry standard for working with real-time data, and discuss three options for streaming data with Python: a Python client for Kafka’s consumer/producer API, the streaming processing framework Python, and the cloud-native data platform DataCater.
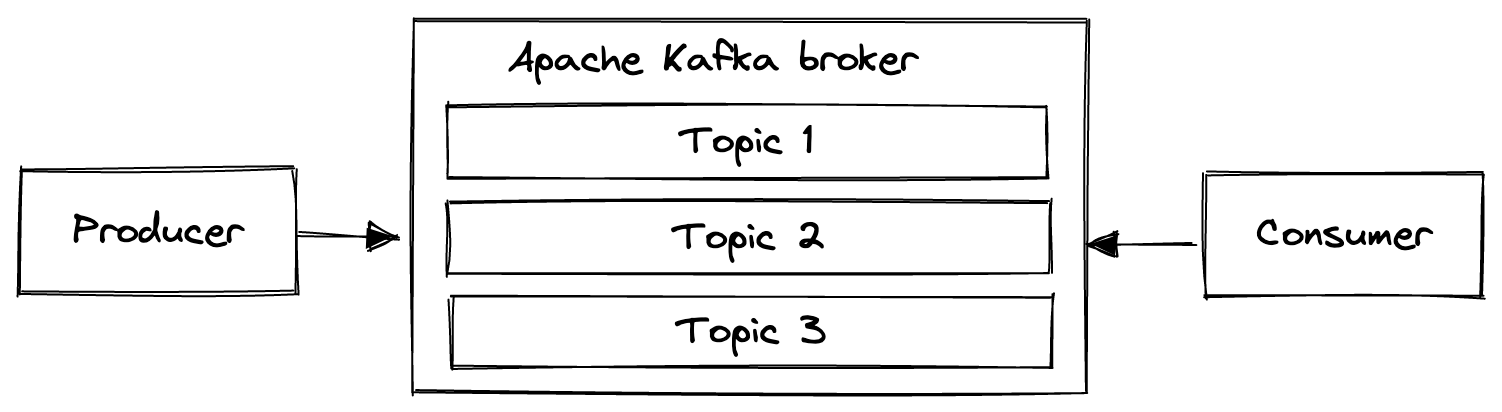
Today, Apache Kafka is the ubiquitous technology for implementing data streaming. Apache Kafka consists mainly of brokers/servers, producers, and consumers. Check their documentation for detailed information on Apache Kafka.
Kafka producers write streams of data to specific topics and consumers at the other end consume streams from subscribed topics. Producers and consumers run outside of the Kafka cluster and can be implemented with SDKs in languages, such as Java, Golang, or Python.
Let’s assume that you have a central log server, which manages logs from different web services. You would want to pull records from specific web services to specific topics. Each topic in the Kafka cluster represents a service in your infrastructure. An example of such a service/topic could be your web server.
In this architecture, the role of the Kafka producer is to publish the logs from your web servers into the web server topic. Consumers can read the log data from the topic and process them in real-time.
Kafka brokers are responsible for managing the topics in a reliable, robust, scalable, and fault-tolerant way.
The data streaming community offers different tools for producing, processing, and consuming streams in Python. They can be used to implement use cases, such as fraud detection, real-time communication, order management in e-commerce, etc.
In the following sections, I introduce three popular options for Python-based data streaming and discuss their pros and cons, hopefully allowing you to make a well-informed choice when choosing a technology for processing data streams with Python.
Apache Kafka provides an official SDK only for Java. Other languages, such as Python, must use SDKs from the community.
The libraries kafka-python and confluent-kafka-python are popular client libraries for working with the producer and consumer API of Apache Kafka in Python.
The following code example shows how to connect to a Kafka broker, running on localhost:9092, with kafka-python and start consuming records, which hold JSON data in their value, from the Kafka topic blog_example. We set a couple of consumer properties, such as auto_offset_reset:
from kafka import KafkaConsumer
from json import loads
consumer = KafkaConsumer(
blog_example,
bootstrap_servers=['localhost:9092'],
auto_offset_reset='earliest',
enable_auto_commit=True,
group_id='unique-consumer-group-id',
value_deserializer=lambda x: loads(x.decode('utf-8')))
for message in consumer:
print('Consumed record with value: {}'.format(message.value))
Kafka-python only offers ways for communicating with Kafka’s consumer and producer API, but does not provide any high-level stream processing capabilities out of the box. While this provides lots of flexibility, developers are in charge of implementing such transformations and processors from scratch themselves, potentially reinventing the wheel all the time.
Faust is a high-level stream processing framework for Python. It was originally built at Robinhood, which seems to have stopped the development. A fork by the open-source community seems to still be under development, though.
Faust is a pure Python client and can be used to build a complete data streaming pipeline with pythonic libraries such as NumPy, PyTorch, Pandas, NLTK, SQLAlchemy, and others. It aims at implementing a similar approach as Kafka Streams in Python.
Faust uses a similar approach as kafka-python. First and foremost, a Faust object needs to be created for connecting with a Kafka broker:
import faust
app = faust.App('demo-app', broker='kafka://localhost:9092')
This bootstrap setting specifies which Kafka broker Faust interacts with. Please note that a Faust application can only work with one Kafka cluster at a time, thus it does not support inter-cluster streaming.
With Faust, you do not need to deal with serializing or deserializing data into or from objects, but can directly work with Python classes.
This allows us to natively model our data and use Python data types, such as int:
class User(faust.Record): user_id: int username: str age: int
Once you have connected with Kafka and defined your data classes, a stream processor agent can be defined as an async function via a Python decorator. These agents (1) consume records asynchronously from a subscribed Apache Kafka topic, (2) process the records using in-built Python processing tools, and (3) publish the processed records to another Apache Kafka topic.
In the following code example, a Faust agent consumes messages from the users topic, filters users below the age of 30, and publishes the filtered records to the topic users_young:
users_topic = app.topic('users', value_type = User)
users_young_topic = app.topic('users_young')
@app.agent(users_topic)
async def process(users):
async for user in users.filter(lambda: v.age < 30):
await users_young_topic.send(user)
Similar to Kafka Streams, Faust also supports more sophisticated stateful streaming processing techniques, like tumbling (link), hopping (link), or sliding windows (link).
Faust comes with an embedded database system known as RocksDB. The Faust agent can use it to persist the state of streams.
As oppossed to kafka-python, Faust offers much more capabilities and abstractions for processing data in real-time, both with stateless and stateful operations. The increased capabilities come at the cost of a slightly reduced flexibility. For instance, Faust cannot stream data between topics of different Apache Kafka clusters.
DataCater is another data streaming tool being used by data practitioners in the industry. While the previously discussed approaches do not make any preference on compute, DataCater is much more opinionated and aims at natively integrating with Kubernetes. Similar to kafka-python and Faust, DataCater allows users to define data transformations in Python. Users can choose from a large set of Python transforms from the community but are also able to develop their own custom transforms in Python.
For trying DataCater out, you can install it on your (local) Kubernetes cluster using the following command:
$ kubectl apply -f https://install.datacater.io/minikube $ kubectl port-forward ui 8080:8080
Once installed, you can access the UI and API under http://localhost:8080.
DataCater offers streams, pipelines, and deployments as building blocks for implementing data streaming. Streams resemble Apache Kafka topics. Pipelines describe the applied data transformations. Deployments take care of running the pipeline description in Kubernetes.
Let’s assume the same example of users that we want to filter and stream between different topics.
In the first step, we need to obtain an access token for working with DataCater’s API:
$ curl -uadmin:admin -XPOST http://localhost:8080/api/alpha/authentication
> {"token_type":"Bearer","access_token":"eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiJ9.eyJpc3MiOiJodHRwczovL2RhdGFjYXRlci5pbyIsInVwbiI6ImFkbWluIiwiZ3JvdXBzIjpbImRldiIsImFkbWluIiwidXNlciJdLCJpYXQiOjE2NjkyNjk4MDUsImV4cCI6MTY2OTI3NzAwNSwianRpIjoiNzMwMWYyYmYtMmNkZS00ODg4LTlhMGMtMzhkZGM1NjYxNWFhIn0.KMJo_rllFupKUR8D7_m-hxR-D4ewUke2c-kKs75K1mJaou28nEfxW3ZZjxCYSlG3WcEb_244vcBBlwYfiHl2Q0dCR09kF9JRDv59c5XlEPViMc0W4Y0pabmNDFDIDlSjEdb43eFOfiJlFMiJYlTlO5lsS54cj5dDe9rxtTUvuXj3_CUDUgORxOJLwdt_BTgdTdJrTLtt3YDMj4oOPLkIULLvojbKGoF7Wssw7i7r5-ffZPvR8ghagWwZDZ53_-E-RfBZYnyP2X9Dk2aN7IJMyLkGd1-5fYmX1_GcjXcRTZA1sDpNGjH7Y0YRsnxH7gtm_Dd42Un2B9XWN4nVvL7EFBhdpF6jnQlU78cShNR2RVNB96XHmZkTyZrRoEwewkIB4kaZ5HYAuKDHmyg5fO91GKBRu2mYdEOe5e91r3wUJhMNUhVZ8Pc-rYPcOqtWCZgzbpf3tT8I4JkT9xEugu8mf7qOoRkIRbGvrV_A5PlyjeKgxkoeQwV9yXl9PQ4vTwXpdi4vAja0P7tzif-fYd8IOdhpGV9PcQAhAkUfC5sU0wgA3Msnvv0DuFzWecePN0IjQ1fafclfu79K-XzofJK-ynPqtWiB4nTPXNuLmRnYFQzyZwBPwCBIAZ5qHzAu1nOpgVa1g3BmIrrjPCkg4TlfzsA0E3looHpk8FM_amj55Rc","expires_in":7200}
Please note the access token and replace YOUR_TOKEN in the
following code examples with it.
Next, we can create the input and output streams:
$ curl http://localhost:8080/api/alpha/streams/ \
-XPOST \
-H'Content-Type:application/json' \
-d'{"spec":{"kind":"KAFKA","kafka":{"topic":{"config":{}},"bootstrap.servers":"localhost:9092"}},"name":"users"}' \
-H'Authorization:Bearer YOUR_TOKEN'
> {"uuid":"c6eea63b-5144-4efc-8a9e-295e33ebc5d0","createdAt":"2022-11-09T10:19:06.052+00:00","updatedAt":"2022-11-11T05:14:23.818+00:00","name":"users","spec":{"kafka":{"topic":{"config":{}},"bootstrap.servers":"localhost:9092","value.deserializer":"io.datacater.core.serde.JsonDeserializer","key.deserializer":"io.datacater.core.serde.JsonDeserializer","key.serializer":"io.datacater.core.serde.JsonSerializer","value.serializer":"io.datacater.core.serde.JsonSerializer"},"kind":"KAFKA"}}
$ curl http://localhost:8080/api/alpha/streams/ \
-XPOST \
-H'Content-Type:application/json' \
-d'{"spec":{"kind":"KAFKA","kafka":{"topic":{"config":{}},"bootstrap.servers":"localhost:9092"}},"name":"young_users"}' \
-H'Authorization:Bearer YOUR_TOKEN'
> {"uuid":"2956168a-1210-483a-bb64-0eb2f4c8ee85","createdAt":"2022-11-09T10:19:06.052+00:00","updatedAt":"2022-11-11T05:14:23.818+00:00","name":"young_users","spec":{"kafka":{"topic":{"config":{}},"bootstrap.servers":"localhost:9092","value.deserializer":"io.datacater.core.serde.JsonDeserializer","key.deserializer":"io.datacater.core.serde.JsonDeserializer","key.serializer":"io.datacater.core.serde.JsonSerializer","value.serializer":"io.datacater.core.serde.JsonSerializer"},"kind":"KAFKA"}}
Please note the UUIDs of the created Stream objects.
When we are using JSON as data format (which is the default in DataCater), we do not have to specify a schema but can let DataCater infer the schema automatically.
DataCater allows users to provide filters and transforms as lightweight Python functions that are applied to records while they are streamed between Apache Kafka topics. Filters and transforms can be applied to single fields of the record or the entire record.
A field-level filter can be defined using the following Python function.
It has access to both the field that it is being applied to as well as
the entire record, both being provided as arguments to the
function:
# field: Value of the field that the transform is applied to. # record: The entire record as Python dict. def filter(field, record: dict) -> bool: # Return whether the transform shall be applied/the record shall be processed or not. return True
An entire pipeline can be defined using the following YAML format. Note that you can directly access fields of records without having to map them beforehand:
name: “Users”
spec:
steps:
- kind: "Field"
fields:
age:
filter:
key: "user-defined-filter"
config:
code: |
def filter(field, record: dict) -> bool:
return field < 30
Using the following curl command, we can send the pipeline spec in the JSON format to the API of DataCater and create a new pipeline object:
$ curl http://localhost:8080/api/alpha/pipelines \
-XPOST \
-H'Content-Type:application/json' \
-d'{
"name":"Filter users",
"metadata":{
"stream-in":"c6eea63b-5144-4efc-8a9e-295e33ebc5d0",
"stream-out":"2956168a-1210-483a-bb64-0eb2f4c8ee85"
},
"spec":{
"steps":[
{
"kind":"Field",
"fields":{
"age":{
"filter":{
"key":"user-defined-filter",
"config":{
"code":"def filter(field, record: dict) -> bool:\n return field < 30"
}
}
}
}
}
]
}
}' \
-H'Authorization:Bearer YOUR_TOKEN'
> {"uuid":"23bf3223-a8e4-4070-a4e0-0c12620dfec3","createdAt":"2022-11-22T05:21:26.166+00:00","updatedAt":"2022-11-22T05:22:13.183+00:00","name":"users","metadata":{"stream-in":"c6eea63b-5144-4efc-8a9e-295e33ebc5d0","stream-out":"2956168a-1210-483a-bb64-0eb2f4c8ee85"},"spec":{"steps":[{"kind":"Field","fields":{"age":{"filter":{"key":"user-defined-filter","config":{"code":"def filter(field, record: dict) -> bool:\n return field < 30"}}}}}]}
In the next step, we can create a Deployment for starting the pipeline in Kubernetes:
$ curl http://localhost:3000/api/alpha/deployments/39f9d275-8ce2-4d30-83a9-ba7819e20e5e \
-XPUT \
-H'Content-Type:application/json' \
-d'{"name":"Users deployment","spec":{"pipeline":"23bf3223-a8e4-4070-a4e0-0c12620dfec3"}}' \
-H'Authorization:Bearer YOUR_TOKEN'
We do not have to specify our code inline, but could also extend the list of pre-defined transforms from DataCater by adding a filter or transform to the respective folder in a local repository of DataCater. When the application starts, it will then automatically pick up our functions and make them available to other users, which makes extending DataCater straightforward and helps with the reuse of existing transformations.
Compared to kafka-python and Faust, DataCater is very opinionated about the compute layer and natively integrates with Kubernetes. If you are running Kubernetes, it can accelerate your data development significantly and ease working with Kubernetes and Apache Kafka. On the other side, if you try to stay away from Kubernetes, DataCater might not be an option for you.
Each tool has its pros and cons.
For instance, kafka-python seems to be the most mature solution - in terms of development and community support - but requires developers to build a lot of functionality from scratch. While Faust provides great stateful stream processing capabilities, it is restricted to use cases where all topics reside on the same Kafka cluster. DataCater might be a great choice if you want to perform serverless data streaming with Python, but has little to offer to teams that avoid Kubernetes.
The following matrix summarizes the strength and features of each tool discussed, which helps you to understand which Python-based streaming tool to use for a specific project:
| kafka-python | Faust | DataCater | |
|---|---|---|---|
| Learning curve | |||
| Speed of development | |||
| Stateful workloads | Only joins |
||
| Usability | |||
| Reusability | |||
| Inter-cluster streaming | |||
| Community support | |||
| License | Apache 2 | BSD | BSL |
| Source code | dpkp/kafka-python | faust-streaming/faust | DataCater/datacater |
Get started with DataCater, for free
The real-time ETL platform for data and dev teams. Benefit from the power of event streaming without having to handle its complexity.