DevOps and DataOps
The ultimate goal of DataOps is to reduce the time needed for developing and deploying data pipelines.
The ultimate goal of DataOps is to reduce the time needed for developing and deploying data pipelines.
In this article, we use the definition of DevOps as “a set of practices intended to reduce the time between committing a change to a system and the change being placed into normal production, while ensuring high quality” (Bass, Len; Weber, Ingo; Zhu, Liming (2015). DevOps: A Software Architect‘s Perspective).
The ultimate goal of DataOps would be to reduce the time needed for developing and deploying data pipelines. Breaking down the parts of the above definition, we can derive tools required to implement automated deployments to production upon code changes in data pipelines.
The status quo of developing and operating data pipelines unveils a couple of conceptual flaws when it comes to automated roll-outs of new pipeline revisions. We addressed two needs of data pipelines, runtime consistency and declarative definition, in former articles. This article focuses on automatically ensuring the quality of changes applied to data pipelines.
Application development in a DevOps fashion ensures high quality by having consistent builds and fully-automated unit, integration, and end-to-end testing of new revisions. Data pipeline developers do not have access to similar tooling and cannot efficiently test changes before rolling them out to production. Reasons for this include:
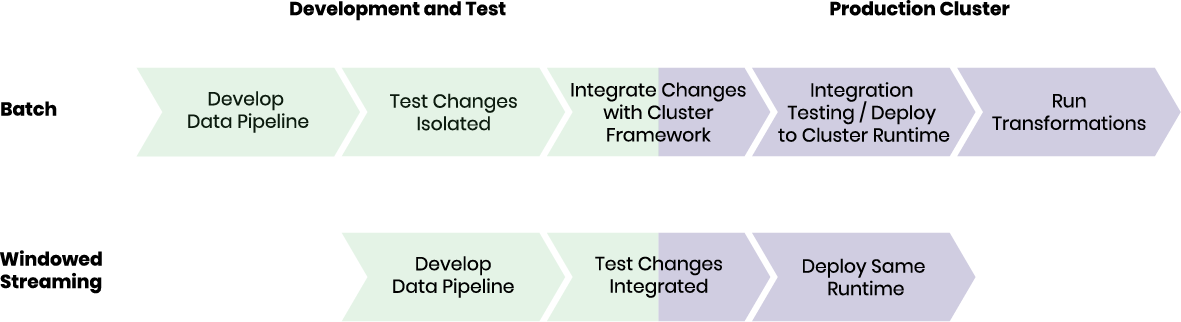
We propose a different approach to processing data. From our experience, most data sets are in motion and change over time. Instead of assuming that a data set can be processed in one go as a batch, we prefer considering data sets as continuous flows of information. As a consequence, we never assume that a data set is complete but always expect that - at a certain time - we can only see a window of an endless stream of data. In other, slightly more technical terms, we suggest perceiving batch jobs as a subset of event streaming where batches might resemble a window, defined by time range or amount of records, of data change event streams.
"Reduce time of data pipeline development iterations by switching to an event streaming execution model."
Moving from batch processing to streaming unlocks automated quality assurance for data pipelines. Container-based data pipelines are self-contained and define their needed resources at deployment time. Self-containment isolates data pipelines from each other and allows an orchestrator, like Kubernetes, to ensure the availability of compute resources before starting the transformation of data.
Windowed streams can be emulated by the same principles as applied in continuous integration pipelines. For efficient testing, you might reduce the size of the window, if your data pipeline requires aggregates. However, there is no need to change the actual code to adhere to a certain specialized test runtime, as the code you test with is the exact same code you run in production.
Want to learn more about the concepts behind cloud-native data pipelines? Download our technical white paper for free!
