Introduction
This guide will help you get started with DataCater! All the important stuff – an introduction to the platform, a list of available transformation functions, or guides on using connectors – is documented here. Should you have any questions, always feel free to reach out to our team at support@datacater.io.
Welcome
Welcome to the real-time, cloud-native data pipeline platform where data and developer teams unlock the full value of their data.
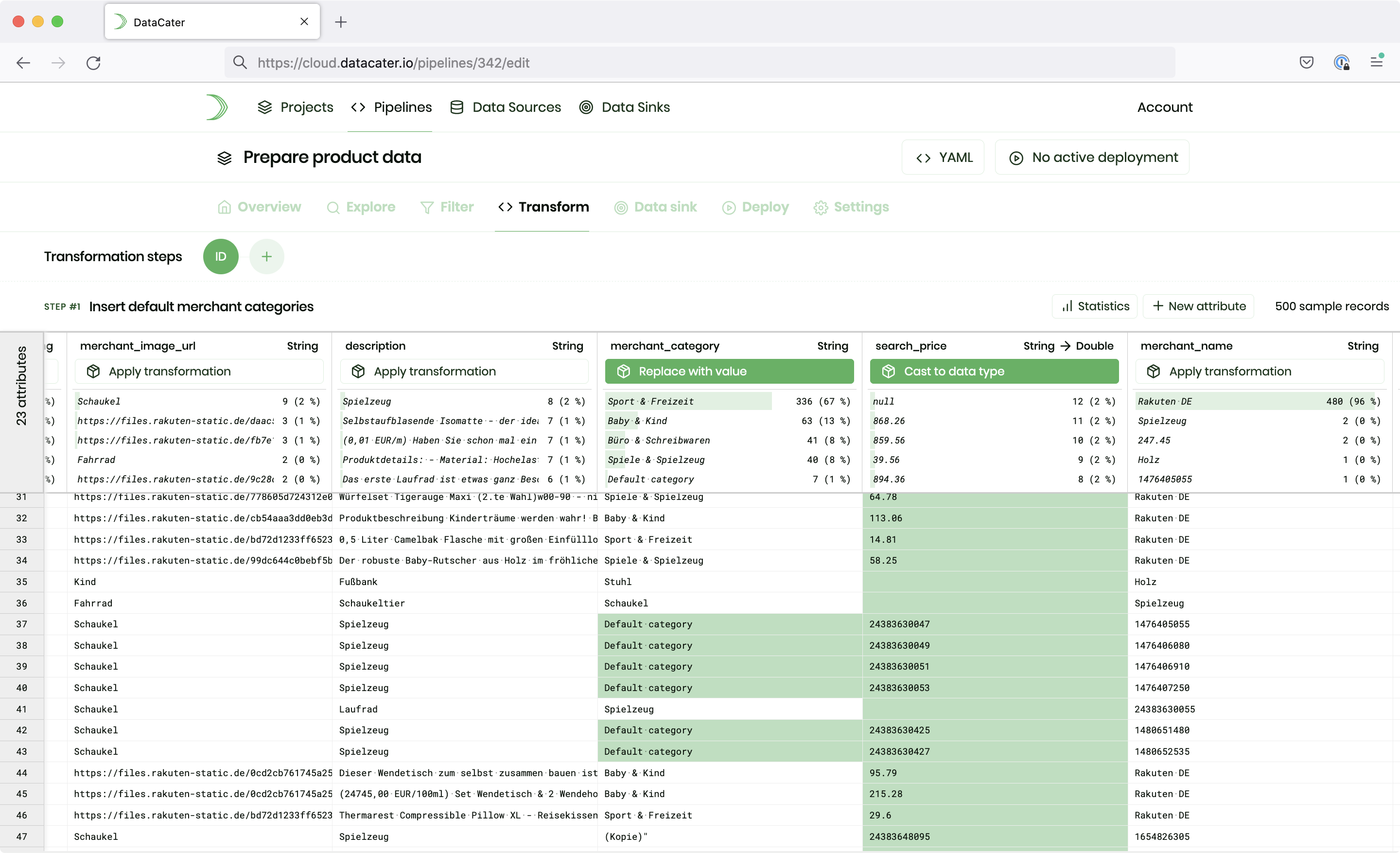

DataCater provides the pipeline designer as an interactive means to building production-grade streaming data pipelines: Users can choose from an extensive repository of filter functions, apply no-code transformations, or code their own transforms in Python to build streaming data pipelines in a matter of minutes. The pipeline designer instantly previews the impact of assembled data pipelines on sample data, which creates full transparency on applied transformations, accelerates the development process, and enables teams of diverse technical backgrounds to use the same tool for working with data. DataCater manages pipeline definitions managed as YAML descriptions.
Technically, DataCater integrates with the ecosystem of Apache Kafka and provides a cloud-native approach to data pipelines. DataCater uses Kafka Connect for integrating external data stores, which does not only allow to reuse many existing connectors but also facilitates the development of custom connectors. It compiles data pipelines to production-grade Kafka Streams applications, which continuously stream data changes from data sources to data sinks and perform transformations on the way. Data pipelines are deployed as containers and integrate natively with private or public cloud platforms.
Features
-
Fast development cycles:
DataCater's pipeline designer allows iterating on data pipelines in seconds and deploying them in minutes. Let us take care of the complexity of data pipelines, so you can focus on your job. -
Change data capture:
Plug-and-play connectors for change data capture (CDC) allow to consume data change events from a plethora of different data systems, e.g., databases, HTTP APIs, file systems, without implementing any custom code. -
Real-time data processing:
DataCater compiles your pipelines to production-grade streaming applications, which can process data in real-time. -
Powerful transformations:
Our first-in-class approach to transformations combines the efficiency of a no-code solution with the power of Python transformations. Implement any data preparation requirement in seconds to minutes. -
Cloud native:
Being built for the cloud era, DataCater Self-Managed natively integrates with your private or public cloud platform and can be operated on your Kubernetes cluster. -
Project-based collaboration:
Unlock the full potential of your team by collaborating on data pipelines. -
Monitoring & notifications:
We continuously monitor the health of connectors and data pipelines and can notify you via e-mail or Slack when something goes wrong. -
Logging:
Access the logs of your data pipelines through our UI to watch transformations being applied to data on the event level and investigate potential issues instantly.
Quickstart
Please head over to the quickstart to get started using DataCater and build your first streaming data pipeline in a couple of minutes.
Questions?
We are always happy to chat data preparation and help with any questions that you have. Please reach out to us at support@datacater.io or join our Community Slack.