Building blocks
Learn more about DataCater's building blocks and concepts for developing streaming data pipelines.
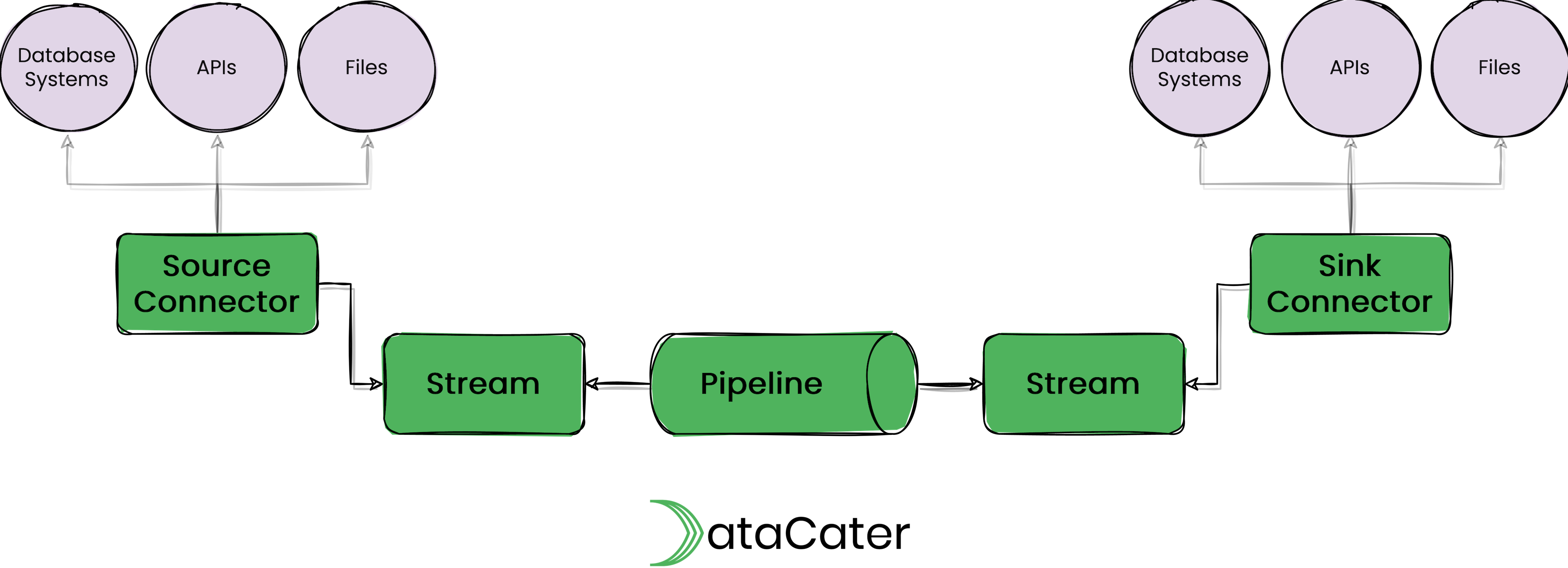
Streams
Streams are sequences of events (or records). Events consist
of a key and a value. They must define
a key.format and a value.format,
e.g., JSON, and might define a schema.
In DataCater Cloud, stream objects are managed by DataCater and cannot be created manually. In DataCater Self-Managed, DataCater can be plugged into an existing Apache Kafka cluster and thus back stream objects by externally-managed Apache Kafka topics.
For the time being, DataCater implements streams as Apache Kafka topics.
Pipelines
Pipelines consume events from one or (in the case of a join) multiple streams, may apply filters and transformations to the events, and publish the transformed events to another stream.
Pipelines expose the Pipeline lag metric, which boils down to Kafka's consumer lag metric. In DataCater's UI, you can view it on the Deploy page. The pipeline lag indicates the number of events of the consumed stream that the pipeline has not yet processed.
DataCater manages pipeline revisions as container images and runs pipelines as Kubernetes Deployments.
Source Connectors
Source connectors extract data from an external system and publish the data to a stream. Most source connectors implement change data capture. Most source connectors maintain the state of the data extraction, e.g., the row of a replication log that they have processed most recently.
DataCater implements source connectors with Apache Kafka Connect.
Sink Connectors
Sink connectors consume events from a stream and publish them to an external system.
Sink connectors expose the Sink connector lag metric, which boils down to Kafka's consumer lag metric. In DataCater's UI, you can view it on the Deploy page. The sink connector lag indicates the number of events of the consumed stream that the sink connector has not yet successfully published to the external system.
DataCater implements sink connectors with Apache Kafka Connect.