Deployments
DataCater's one-click deployments are your fast lane to production.
Once you've implemented all your data preparation needs, you can turn your pipeline into executable code by creating a deployment. Creating a deployment compiles your pipeline to a production-grade streaming application, powered by Apache Kafka Streams, which is released as an immutable container image.
Once created, you can start the execution of the deployment by clicking one button.
Naming
Like most objects in DataCater, you can name your deployment to easily identify it later on.
Versioning
Deployments are a means to versioning your pipeline. You can manage multiple deployments (or version) of your pipeline. However, you can execute only one deployment at the same time. The executed deployment is also called active deployment.
Logs
You can observe the logs of an active deployment by clicking the button Logs in the deployments section of the Pipeline Designer:
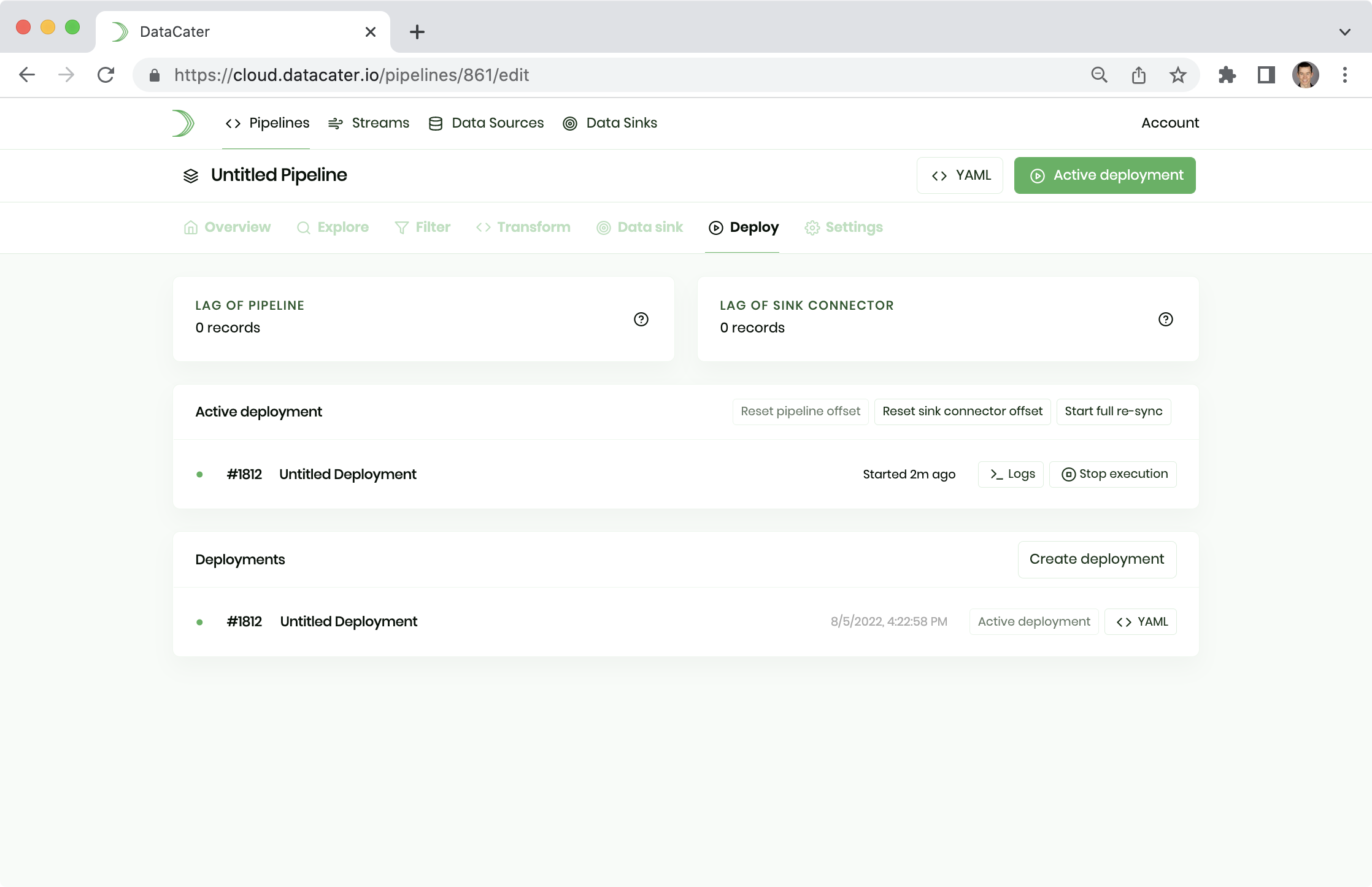
For each processed record, deployments produce a log statement with information on the processing time and the processed data. Logs show when the processing of a record fails or when a record does not pass a pipeline filter.