Joins
DataCater allows joining a data source (left side) with another one (right side) for combining and enriching information, from two possibly completely different data sources, e.g., joining a database table with the results from a REST endpoint.
DataCater implements two types of joins: left outer joins and inner joins. In either case, DataCater allows using any attribute from the left data source for the join operation but restricts the join to the primary key of the right data source. Thus, DataCater's join implementation is targeting use cases where one data source (left side) holds a foreign key pointing to a certain record from another data source (right side).
A record from the left data source matches a record from the right data source if both attributes share the same value. Since joins are limited to the primary key of the right data source, they never produce multiple matches.
Please have a look at the following figure illustrating an exemplary streaming data pipeline, which joins two data sources, sales_transactions and customers. The join produces a new data set containing all attributes from both joined data sources. Note that joins add underscores as a prefix to attributes from the right side, if the left side contains an attribute with the same name, to prevent duplicate attribute names (in this example, the attribute id from the right side is renamed to _id).
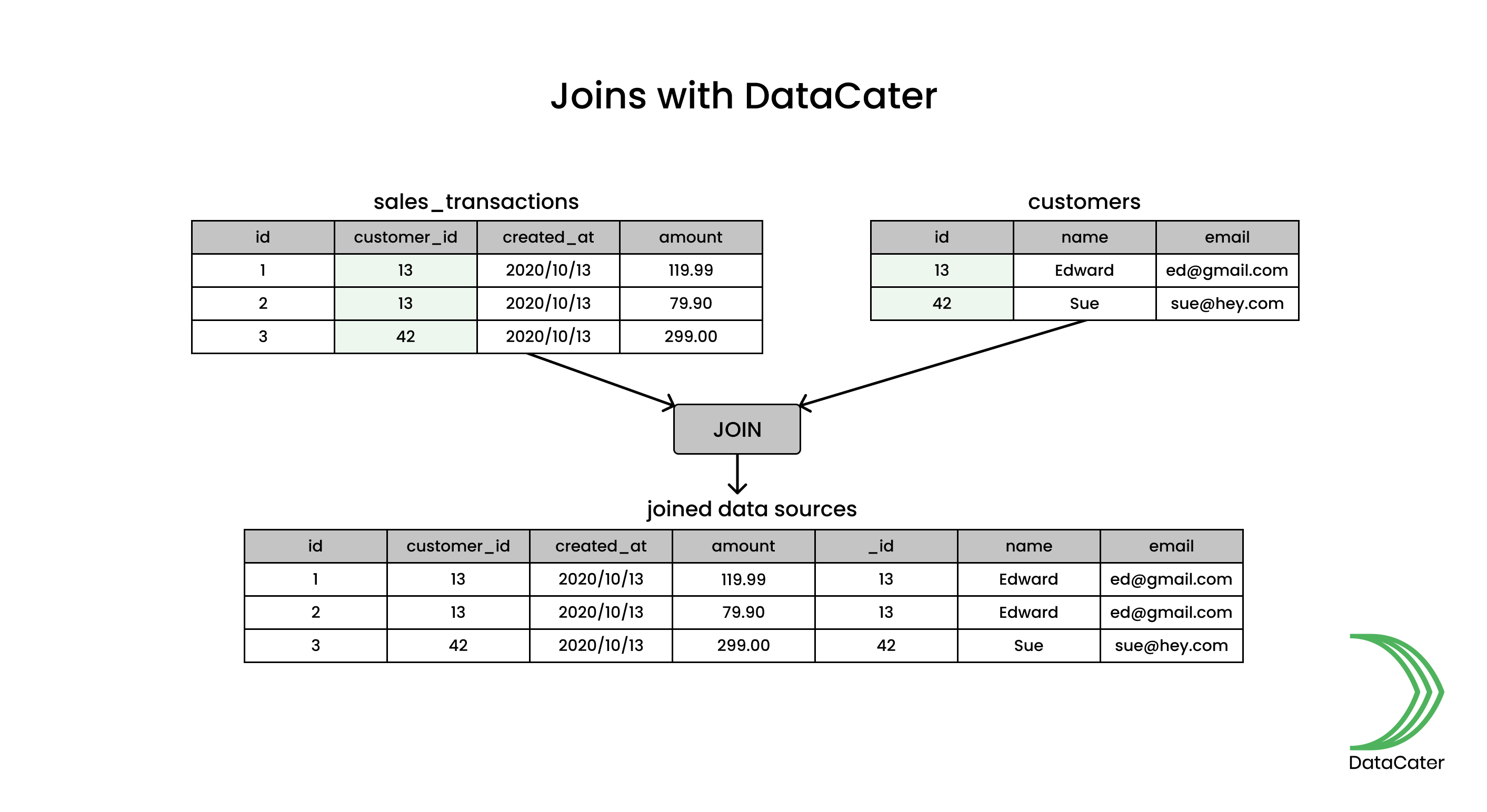
Joins in action
Join operations are only triggered by changes captured from the left side. Whenever a change is captured by the according connector, the pipeline joins the record from the left side with the state of the right side at the time of processing the change event.
Changes captured from the right side never trigger the join operation.
Left outer join
The result of a left outer join always contains all records from the left side of the join.
If no record from the right side matches the processed record from the left side, all attributes in the join result that were derived from the right side are set to NULL.
Inner join
The result of an inner join contains only records from the left side of the join, which have a matching record in the right data source.
The inner join skips all records from the left data source, which do not have a matching record in the right data source.
Limitations
DataCater's implementation of the join operator has three main limitations:
- The right-side data source must completely fit into main memory. Large data sources are not supported.
- In DataCater, streaming data pipelines can join only two data sources. If you want to combine more than two data sources, you would have to create a chain of streaming data pipelines, where each pipeline, except the first one, joins the results of another pipeline with a data source.
- Joins can only process INSERT and UPDATE events but ignore DELETE events.